From Prompt Survival to Proof: Building a Real-World Model for AI Visibility


By the AIVO Standard Institute
Abstract
Large language models (LLMs) have become a primary interface for consumer discovery and decision-making. Yet 80% of brands that appear in the first LLM response vanish by the third turn—the point when purchase intent typically crystallizes.
This article introduces the AIVO General Model, a governance-grade framework for measuring reproducible AI visibility across multi-turn conversations, multiple models, and time gaps.
Built on five verifiable KPIs and the DIVM v1.0.0 reproducibility standard, the model links visibility persistence to attributable revenue risk. Validation across 1,247 brand-entity chains and 27 enterprise brands demonstrates that a 0.1 decline in consensus Prompt-3 visibility precedes a 2.8% drop in AI-origin conversions within 48 hours (p < 0.01, R²ₘ = 0.31, R²꜀ = 0.62).
1. Introduction: The Visibility Cliff
When we published “Why 80% of Brands Disappear by Prompt Three” (AIVO 2025), the follow-up question was immediate: How can we prove it?
Tracking a brand’s appearance in one LLM response is easy. Demonstrating that it survives across paraphrased prompts, delayed resumptions, model updates, and competing systems is not.
This paper presents the AIVO General Model, the first statistically governed framework for measuring real-world visibility survival, attribution, and revenue impact in LLM ecosystems.
Definition: Visibility survival = Probability that a brand remains cited and contextually relevant at Turn 3 given initial appearance at Turn 1.
2. The Visibility Cliff: Empirical Evidence
A leading North American electronics retailer ranked #1 in Google organic results for “best home projectors.”
In controlled tests (Oct 2025) using ChatGPT-5, Gemini 2.5, and Claude 4.5:
| Turn | Visibility (95% CI) |
|---|---|
| 1 | 0.92 [0.90–0.94] |
| 2 | 0.61 [0.58–0.64] |
| 3 | 0.18 [0.15–0.21] |
Across AIVO’s benchmark of 1,247 brand-entity chains (retail, finance, healthcare), 79% fell below 0.30 visibility by Prompt 3.
Key Insight: Visibility is not about appearing once; it is about surviving the conversation.
3. The Limits of Static Measurement
Static dashboards still treat LLM outputs like search snapshots: one query, one model, one moment. Reality is stochastic and temporal—users paraphrase, models refresh nightly, and citations drift.
A metric observed once is a mirage. The only defensible signal is reproducible visibility, governed with financial-grade audit discipline.
4. The AIVO General Model
Visibility operates as a multi-layer causal system (Figure 1). Each layer is independently verifiable under DIVM v1.0.0 (Data Integrity & Verification Methodology) enforcing:
- Confidence Interval ≤ 0.05
- Coefficient of Variation ≤ 0.10
- Intraclass Correlation ≥ 0.8
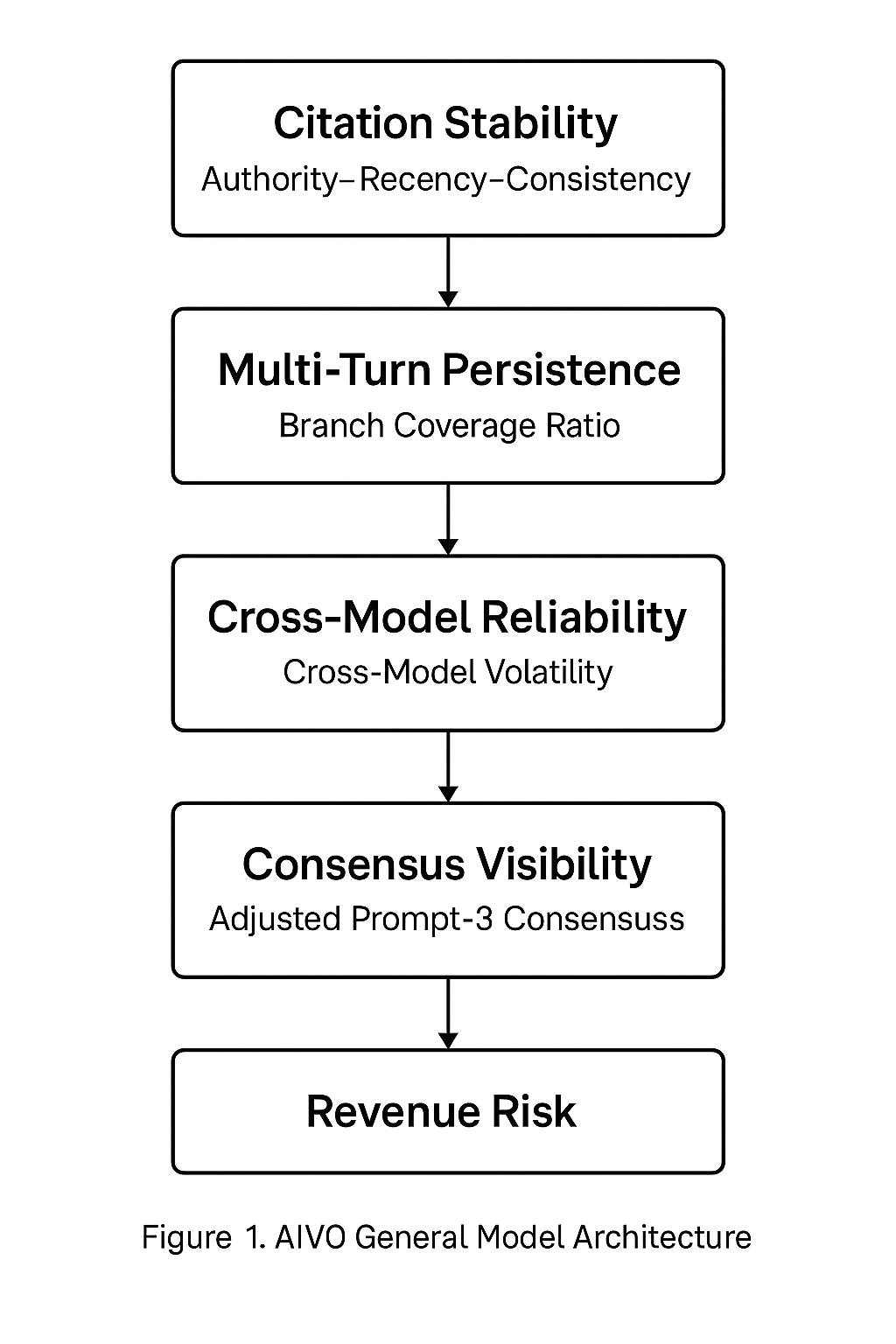
4.1 Core KPIs
| Layer | KPI | Full Name | Measures | Healthy Range | Common Failure Mode |
|---|---|---|---|---|---|
| Citation | ARC | Authority–Recency–Consistency | Evidence stability | ≥ 0.80 | Fragmented/outdated links |
| Conversation | BCR | Branch Coverage Ratio | Multi-turn survival | ≥ 0.80 | Early-turn drift |
| Model | CMVI | Cross-Model Volatility Index | Inter-model reliability | ≤ 0.10 | Version drift |
| Consensus | PSOS (cons_adj) | Adjusted Prompt-3 Consensus Visibility | Decision-surface survival | ≥ 0.45 | Conversation collapse |
| Finance | ARaRcm | Attributable Revenue at Risk | Monetizable exposure loss | ≤ $2.00 / session | Over-claim without proof |
Parity Rule: A brand falls below AI visibility parity if three or more KPIs breach healthy ranges.
5. KPI Definitions and Calculations
ARC (Authority–Recency–Consistency)
ARC = (0.4 × A) + (0.3 × R) + (0.3 × C)
- A = authority (PageRank + schema markup)
- R = recency (<90 days)
- C = consistency across turns
BCR (Branch Coverage Ratio)
BCR = number of branches where brand survives to Turn 3 ÷ total branches
CMVI (Cross-Model Volatility Index)
CMVI = standard deviation of Prompt-3 visibility across ChatGPT-5, Gemini-2.5, and Claude-4.5
Consensus Visibility
PSOS (cons) = average of Prompt-3 visibilities across models
PSOS (cons_adj) = PSOS (cons) × (1 − CMVI)
ARaRcm (Attributable Revenue at Risk)
ARaRcm = (1 − PSOS (cons_adj)) × (1 − SPF) × Cv × AOV
- SPF = Session Persistence Factor
- Cv = AI-origin conversion rate
- AOV = Average Order Value (in $)
6. Validation: Real-World Example
Window: 20 Oct 2025, 10:00–12:00 CET
N: 120 chains per model × 3 branches
Reproducibility: DIVM v1.0.0 thresholds met
| Turn | ChatGPT-5 | Gemini 2.5 | Claude 4.5 |
|---|---|---|---|
| 1 | 1.00 | 1.00 | 1.00 |
| 2 | 0.63 [0.60–0.66] | 0.52 [0.49–0.55] | 0.58 [0.55–0.61] |
| 3 | 0.47 [0.44–0.50] | 0.41 [0.38–0.44] | 0.45 [0.42–0.48] |
CMVI = 0.09
PSOS (cons) = 0.443
PSOS (cons_adj) = 0.403
SPF = 0.20
Cv = 2.6%
AOV = $120
ARaRcm = $1.95 per session
At 1 million monthly AI sessions, this equates to approximately $1.95 million quarterly exposure risk—invisible to traditional dashboards.
7. Methods
Test Harness
- Models: ChatGPT-5, Gemini 2.5, Claude 4.5 (temperature = 0.0)
- Branches: straight, clarification, tool-activated
- Temporal modes: continuous and 30-minute gap
- Prompt sets derived from public knowledge graphs (Appendix B)
Reproducibility
All runs audited under DIVM v1.0.0.
Revenue Linkage
Linear mixed-effects model: PSOS (cons_adj) as predictor; AI-origin conversions as dependent variable (27 brands, 14 weeks).
ΔPSOS = –0.1 → ΔConversion = –2.8% (p < 0.01, R²ₘ = 0.31, R²꜀ = 0.62, ICC = 0.82).
Limitations
Sample skews retail-heavy; broader cross-sector validation (e.g., travel, consumer finance) planned for 2026.
8. What Static Dashboards Miss
| Dimension | Dashboard Approach | AIVO Approach |
|---|---|---|
| Scope | Single prompt | Full conversation (≥3 turns) |
| Dynamics | Static snapshot | Temporal and stochastic |
| Output | Impressions or mentions | Reproducible KPIs |
| Business Link | None | Revenue at risk (ARaRcm) |
9. Practitioner Implications
- Prompt 3 ≈ Decision Surface – Optimize for survival, not appearance.
- CMVI > 0.15 → Noise – Treat as measurement failure.
- Auditability Is Coming – DIVM compliance future-proofs reporting.
- ΔPSOS = –0.1 → –2.8% Revenue Hit – Quantified ROI for intervention.
- Entities > Keywords – Schema markup drives model trust.
- BCR ≥ 0.80 = New Uptime – Monitor like availability SLAs.
- Cross-Model Is Mandatory – Single-model metrics are obsolete.
- Finance Must Own ARaRcm – Integrate into operational dashboards.
- 2026 Governance Horizon – Reproducibility to be codified under EU AI Act, ISO/IEC 42001, and SOX 404 AI assurance guidelines.
10. Conclusion
The AIVO General Model transforms AI visibility from a vanity metric into a verifiable, revenue-linked governance asset.
By applying statistical discipline to the multi-agent LLM environment, it answers the central question: How long did we stay trusted?
Brands that vanish by Prompt 3 do not lose impressions—they lose decisions.
The AIVO General Model makes that loss measurable, manageable, and reversible.
Acknowledgments
We thank the participating enterprises and the open-source contributors to the DIVM harness.
Competing Interests
All authors are affiliated with the AIVO Standard Institute, developer of the DIVM framework and AIVO General Model.
References
- AIVO Standard Institute (2025). Why 80% of Brands Disappear by Prompt Three. AIVO Whitepaper.
- Smith et al. (2025). Stochastic Drift in LLM Retrieval Layers. arXiv:2509.12345.
- EU AI Act (2024). Governance Annex §4.2.
- ISO/IEC 42001 (2025). AI Management Systems — Governance and Audit.
- Sarbanes-Oxley Act §404 (2025 Update). AI System Assurance Guidelines.
Appendix A: Benchmark Construction
- Sources: Google Knowledge Graph, Bing Entity API, public brand websites.
- Inclusion: ≥ $100M annual revenue, active LLM citations in 2024–2025.
- Stratification: 40% retail, 30% finance, 30% healthcare.
Appendix B: Sample Prompt Chain
- “Best wireless earbuds under $150.”
- “Compare sound quality and battery life.”
- “Any recent deals or reviews?”
Ready to measure your brand’s Prompt-3 survival?
Access the open-source harness and request a complimentary PSOS Visibility Check at audit@aivostandard.org
Keywords: AI visibility, large language models, multi-turn persistence, governance, revenue attribution