Making AI Reasoning Inspectable Without Arguing Truth

AIVO Journal — Governance Commentary
As AI systems become operationally influential, the central risk is no longer whether they can generate fluent answers. It is whether their reasoning can be inspected after the fact.
Enterprises are now routinely affected by external AI systems they do not control: large language models mediating product comparisons, vendor assessments, eligibility framing, and risk narratives. These systems shape outcomes long before any human review occurs. Yet when those outcomes create exposure, enterprises are often left with a familiar and inadequate explanation:
“That’s just how the model answered.”
This is no longer acceptable to boards, regulators, insurers, or courts.
The core governance problem is not hallucination. It is uninspectable reasoning.
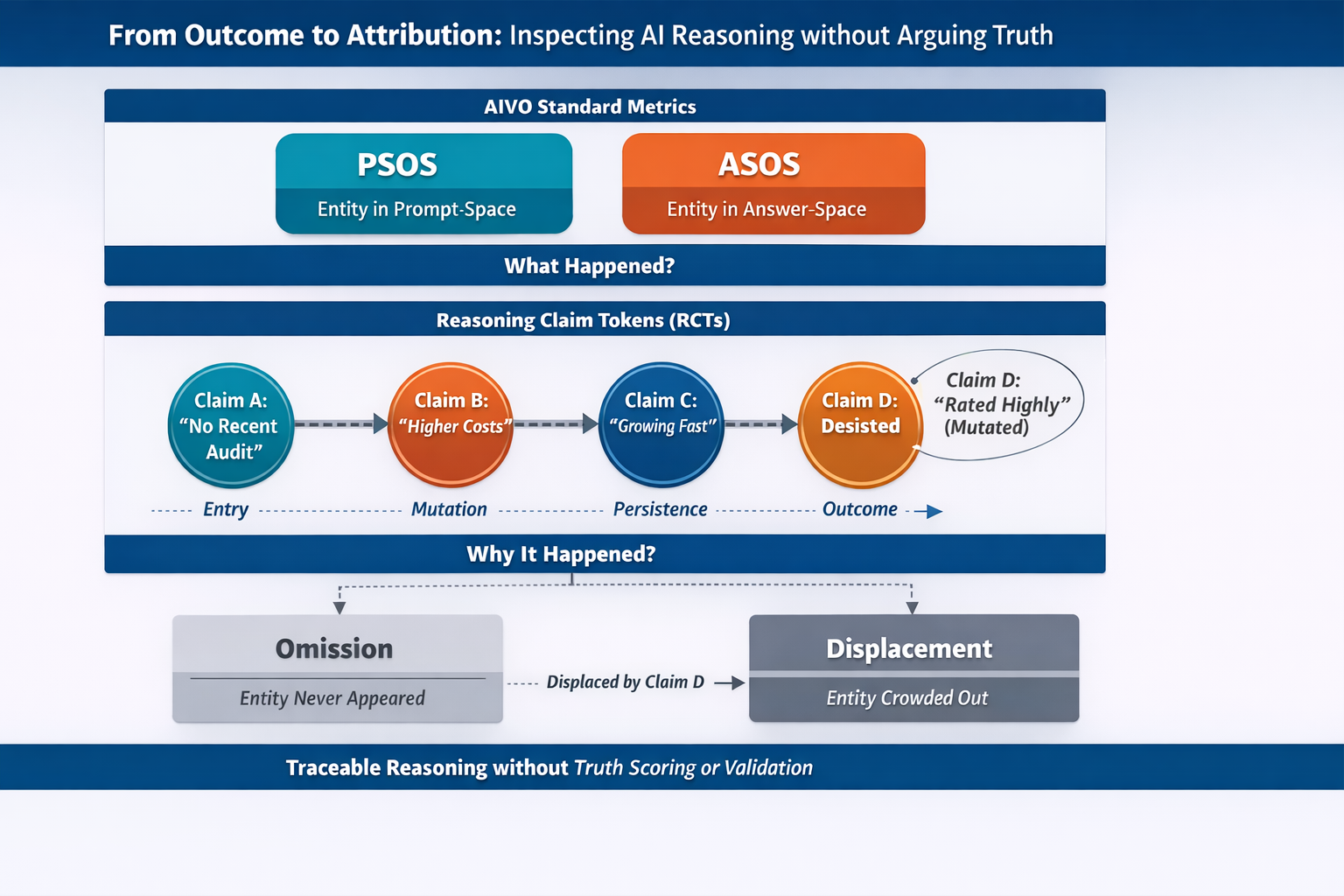
What AIVO Already Measures
The AIVO Standard was designed to govern external AI representation risk without intervening in model behavior.
It does so through two core measures:
- Prompt-Space Occupancy Score (PSOS): whether an entity is present in the prompt-space across a defined decision journey.
- Answer-Space Occupancy Score (ASOS): whether that entity is selected, surfaced, or excluded in the answer-space.
Together, PSOS and ASOS show what happened to an entity inside AI-mediated decision flows.
They deliberately do not attempt to explain why.
That omission is intentional. Explanation without discipline quickly becomes judgment. Judgment invites liability.
But as AI exposure has intensified, a clear gap has emerged.
The Attribution Gap
When an enterprise is excluded, downgraded, or mischaracterized by an AI system, stakeholders inevitably ask:
- What assumption entered the reasoning path?
- When did it appear?
- Did it persist or mutate across turns?
- What was present when the outcome occurred?
Without claim-level visibility, these questions cannot be answered with evidence. They are filled instead with narrative, speculation, or model folklore.
This is the attribution gap: outcomes are observable, but the reasoning context in which they emerged is not.
Closing that gap requires inspection, not correction.
Reasoning Claim Tokens (RCTs)
To address this, the AIVO Standard introduces Reasoning Claim Tokens (RCTs).
A Reasoning Claim Token is a discrete, time-indexed unit of reasoning expressed by an AI system during inference, representing a claim, assumption, comparison, or qualification that is present within downstream reasoning or selection contexts.
RCTs capture what the system reasoned with, not whether that reasoning was correct.
They are observational artifacts, not judgments.
Each RCT records:
- when a claim entered the reasoning sequence,
- how it was expressed in observable language,
- whether it persisted, mutated, or disappeared across turns,
- and its association with observable selection outcomes.
RCTs are derived exclusively from observable model outputs. They do not rely on privileged access to internal chain-of-thought, latent representations, or proprietary reasoning traces.
RCTs do not assert causality. They record presence.
What RCTs Explicitly Do Not Do
Because boundaries matter, the AIVO Standard is explicit about what RCTs are not.
RCTs do not:
- determine factual correctness,
- assign confidence, consensus, or truth scores,
- validate claims against authoritative sources,
- steer, anchor, or alter model outputs,
- constitute evidence of regulatory compliance or factual accuracy.
Those functions belong to verification, optimization, or internal control systems. AIVO intentionally operates above those layers.
RCTs exist solely to support inspection, attribution, and auditability.
How RCTs Fit Within the AIVO Standard
RCTs operate beneath PSOS and ASOS as a claim-level observation layer.
- PSOS shows whether an entity was present.
- ASOS shows whether it was selected or excluded.
- RCTs show which reasoning claims were present when those outcomes occurred.
This enables a critical governance distinction:
- Omission: an entity never appeared in the reasoning context.
- Displacement: an entity was crowded out by another claim present in the reasoning path.
That distinction is central to risk classification, incident response, and board-level understanding.
Why This Matters for Enterprise Governance
Enterprise AI risk rarely arises because models generate incoherent language. It arises because decisions cannot be reconstructed.
When reasoning cannot be inspected:
- accountability collapses,
- oversight becomes performative,
- exposure becomes unmanaged.
RCTs restore traceability without asserting truth. They allow enterprises to demonstrate what an AI system reasoned with at a given moment, across models and sessions, using observable language alone.
This supports oversight, not compliance determination. It enables internal controls, remediation, and governance review by making external reasoning visible.
RCTs in Practice
In early AIVO audits, RCTs are used selectively and materially:
- to localize drift within multi-turn journeys,
- to explain exclusions without speculating on intent,
- to support post-incident review and risk reporting.
They are not a headline feature. They are an evidentiary reinforcement.
Observation Beats Correction
There is a persistent temptation in AI governance to fix outputs rather than understand them. That temptation is understandable and often misplaced.
Correction creates responsibility.
Observation creates accountability.
Observation does not replace internal controls or remediation. It enables them by making external reasoning inspectable.
The AIVO Standard is built on this principle.
Reasoning Claim Tokens are not about proving who is right. They are about making it possible to show what happened, when it happened, and what shaped the outcome.
That is the minimum requirement for trust in an AI-mediated world.
