The Evidence: A Record of Observed Behaviour in External AI Systems

Why this record exists
External AI systems now generate decision-relevant descriptions of enterprises on a continuous basis. These descriptions influence purchasing decisions, risk assessments, regulatory understanding, and reputational trust, often before stakeholders engage with any owned or official enterprise channels.
Despite this influence, such representations are typically ephemeral, non-logged, and non-reproducible from the perspective of the enterprise being described. The purpose of this record is not to interpret, assess, or judge AI behaviour, but to document what has been observed, repeatedly and systematically, across models, time windows, and sectors.
This article summarises a consolidated evidentiary record accumulated during a structured research programme and establishes a temporal reference point for subsequent governance discussion. The evidence predates the introduction of any system designed to preserve or govern such records .
Scope of the evidence corpus
The evidence described here is drawn from a six-month structured observation programme conducted during 2025. The corpus comprises over 3,700 pages of preserved primary AI outputs, generated through thousands of controlled, multi-turn prompt executions.
Observation covered more than 50 enterprises across regulated and non-regulated sectors, including pharmaceuticals, financial services, consumer goods, and technology. Enterprises were selected based on market presence and relevance to decision-adjacent user queries, not on known performance issues, regulatory actions, or prior outcomes.
Multiple leading frontier and production AI models were observed across repeated time windows, including executions separated by weeks or months.
Material outputs from this programme were preserved contemporaneously as primary evidence, forming a durable corpus exceeding 3,700 pages.
Page count reflects preserved AI output length and associated contextual material, not unique prompt count.
Method of observation
Observation was conducted using repeatable methodologies intended to reflect realistic user decision conditions rather than artificial test environments.
Key characteristics of the observation method included:
- Fixed prompt structures reused across time windows
- Multi-turn conversational sequences rather than isolated single queries
- Controlled execution parameters
- Time separation between repeated runs
- Observation across multiple model versions
To reduce subjectivity, behavioural classification was conducted by a primary researcher and reviewed for consistency across repeated observations. Where ambiguity existed, outputs were retained but not categorised.
The following were explicitly excluded from the methodology:
- Content injection or prompt steering
- Optimization or ranking techniques
- Feedback loops or reinforcement strategies
- CMS integration or publication mechanisms
- SEO, GEO, or AEO tooling
- Post-hoc editing, selection, or filtering of outputs
Control queries involving unambiguous, well-documented entities were also executed. These confirmed that the systems under observation were capable of producing stable and accurate representations where source material was clear and consistent.
Categories of observed behaviour
Across the evidence corpus, several recurring categories of behaviour were observed. These categories are descriptive and classificatory only. They do not imply intent, fault, or correctness.
Substitution without disclosure
AI systems repeatedly substituted one enterprise, product, or service for another in comparative or recommendation-style queries, without disclosing the basis for substitution.
Suppression or omission
Materially relevant enterprises were omitted entirely from category or “best in class” responses, despite relevance to the stated query.
Misclassification
Enterprises or products were represented using incorrect, outdated, or conflated regulatory, safety, or operational classifications.
Ungrounded or undisclosed assertions
Statements were generated without disclosed sourcing or evidentiary grounding, while being presented in a definitive or authoritative manner.
Temporal inconsistency
Identical prompts sometimes produced materially different outputs when executed across different time windows, absent any known changes to the enterprise being described.
Cross-model divergence
The same decision-adjacent queries yielded conflicting representations across different AI models operating contemporaneously.
Persistence and reproducibility
Individual AI outputs were frequently non-reproducible. However, the behavioural patterns described above were observed repeatedly:
- Across multiple enterprises
- Across multiple sectors
- Across different AI models
- Across repeated executions over time
- Including following unrelated model updates
This persistence indicates structural characteristics of external AI behaviour under decision-adjacent conditions, without asserting causality.
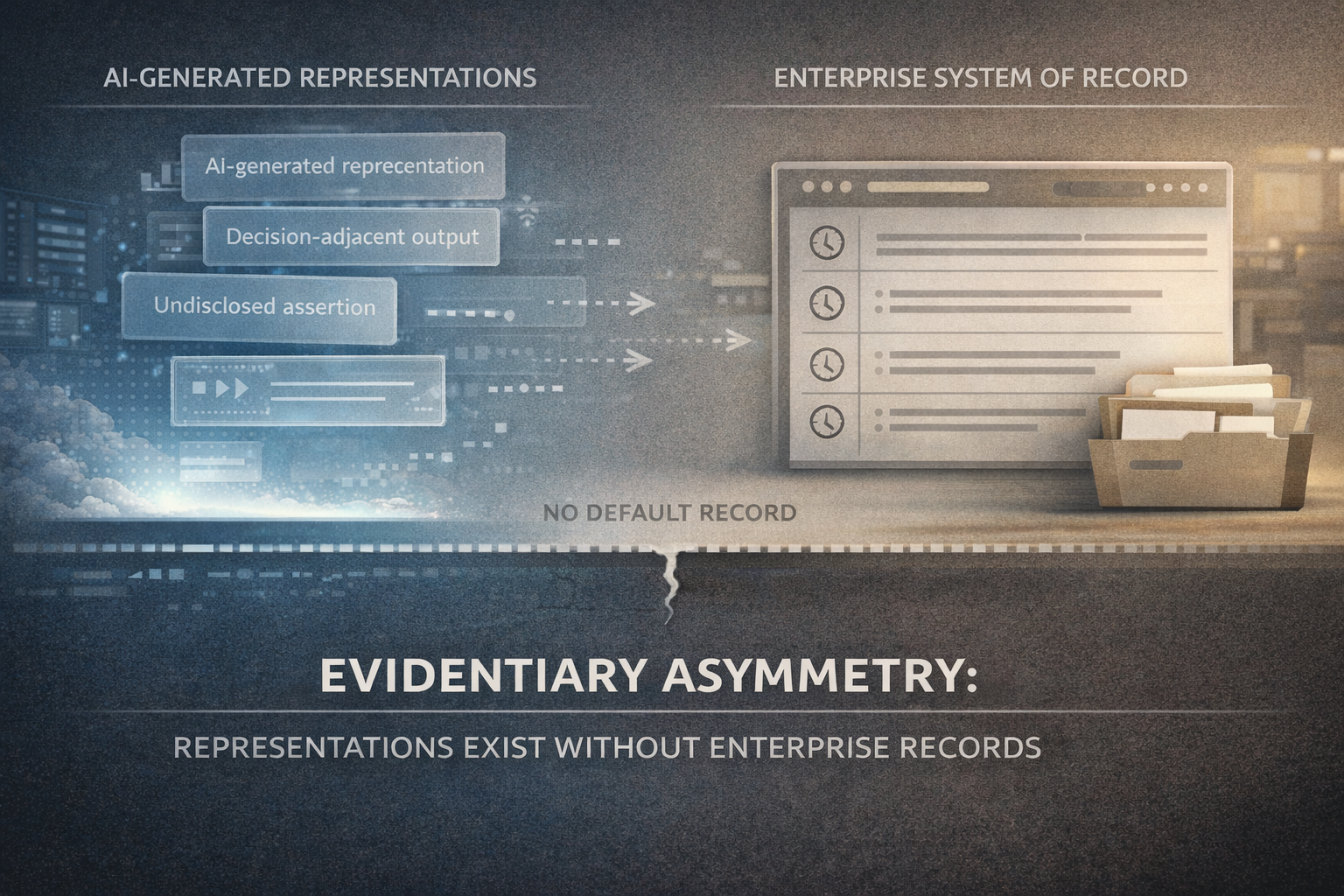
Evidentiary asymmetry
A consistent evidentiary asymmetry was observed between end users and the enterprises being described.
End users may retain:
- Chat histories
- AI-generated documents
- Screenshots or summaries
The enterprise being described typically retains:
- No record of the interaction
- No contextual information
- No timestamped evidence
- No awareness the interaction occurred
In future disputes, inquiries, or regulatory scrutiny, relevant evidentiary material may therefore exist entirely outside the organisation’s possession or control.
Correction and assurance pathways
As of the observation period covered by this record (2025), when AI systems generated inaccurate or misleading representations relating to:
- Regulatory status
- Product safety or indications
- Financial performance
- Partnerships or competitive positioning
There was typically:
- No standardized correction mechanism
- No confirmation of receipt
- No auditable trail of response
- No durable record demonstrating attempted remediation
Even where enterprises might have acted to correct or clarify representations through available channels, no standard mechanisms existed to preserve evidence of such attempts.
Concentration of exposure in regulated sectors
In regulated industries, the observed behaviours carried heightened consequences due to the interaction between AI-mediated representation and existing accountability expectations.
Observed risk amplification included:
- Blurred product distinctions
- Incorrect safety or indication descriptions
- Misstated regulatory status
- Conflated or outdated disclosures
These effects occurred in the absence of default visibility, monitoring, or evidentiary controls available to the enterprise.
Limits of the evidence
This record does not establish:
- Intent or design choices by AI system developers
- Accuracy or inaccuracy of any individual output
- Causality between AI representations and specific enterprise outcomes
- Compliance or non-compliance with any regulatory framework
The evidence documents observable behaviour only. Interpretation, risk classification, and governance response are separate questions and are not addressed here.
Temporal scope and limits of interpretation
This record is published now because the accumulated evidence represents a sufficiently robust corpus to establish baseline behavioural patterns across external AI systems. It documents the state of AI-mediated enterprise representation as observed during 2025 and provides a fixed temporal reference point against which future observation and governance mechanisms may be evaluated.
The publication of this record does not assert that these behaviours are permanent, universal, or uncorrectable. It establishes that they were observable, persistent, and undocumented at the time of observation.
Closing statement
The existence of this evidentiary record does not imply failure by enterprises, AI developers, or regulators. It demonstrates a structural gap between AI-mediated influence and enterprise evidentiary capability.
How that gap should be addressed is a matter of governance design and institutional response. This record exists to document what was observable before any such response is applied.
