When Identical Prompts Produce Opposite Winners

Platform Divergence and Decision-Stage Instability in Tier 1 Banking
AIVO Journal — Banking Case Series
Abstract
Controlled cross-model testing across Tier 1 banking institutions demonstrates that identical comparative prompts can yield materially different decision-stage recommendations across leading AI systems.
Under fixed prompt sequences and repeated runs, we observe:
- Deterministic convergence in some systems
- Progressive recommendation hardening in others
- Explicit winner oscillation in at least one system
- Rubric expansion and authority loading across repeated runs
No institution exhibited universal disadvantage across the ecosystem. Instead, platform-dependent divergence and run-level instability were observed.
This article does not assert bias or systemic targeting. It documents reproducible structural behaviour and examines whether institutions may wish to formalise visibility and assurance over externally generated AI representations when such outputs participate in decision formation.
1. Test Structure
Testing was conducted under controlled conditions:
- Pre-defined scenario classes mirrored across institutions
- Identical competitor framing within each scenario
- Fixed repetition count per system
- No run exclusions other than documented technical failures
- Contemporaneous timestamped preservation
- No post-processing or re-ranking of outputs
Recurrence was defined as:
≥4 of 5 identical decision-stage outcomes under identical prompt conditions.
The framework measures observable recurrence and drift.
It does not assess institutional merit, competitive strength, or model intent.
2. Category 3: Treasury Partner Selection
Tier 1 Institution A vs Institution B
Prompt archetype:
“Which bank is a better partner for a medium-sized enterprise’s treasury and cash management needs in the Nordics: Institution A or Institution B?”
Three runs per model. Identical prompt. No variation.
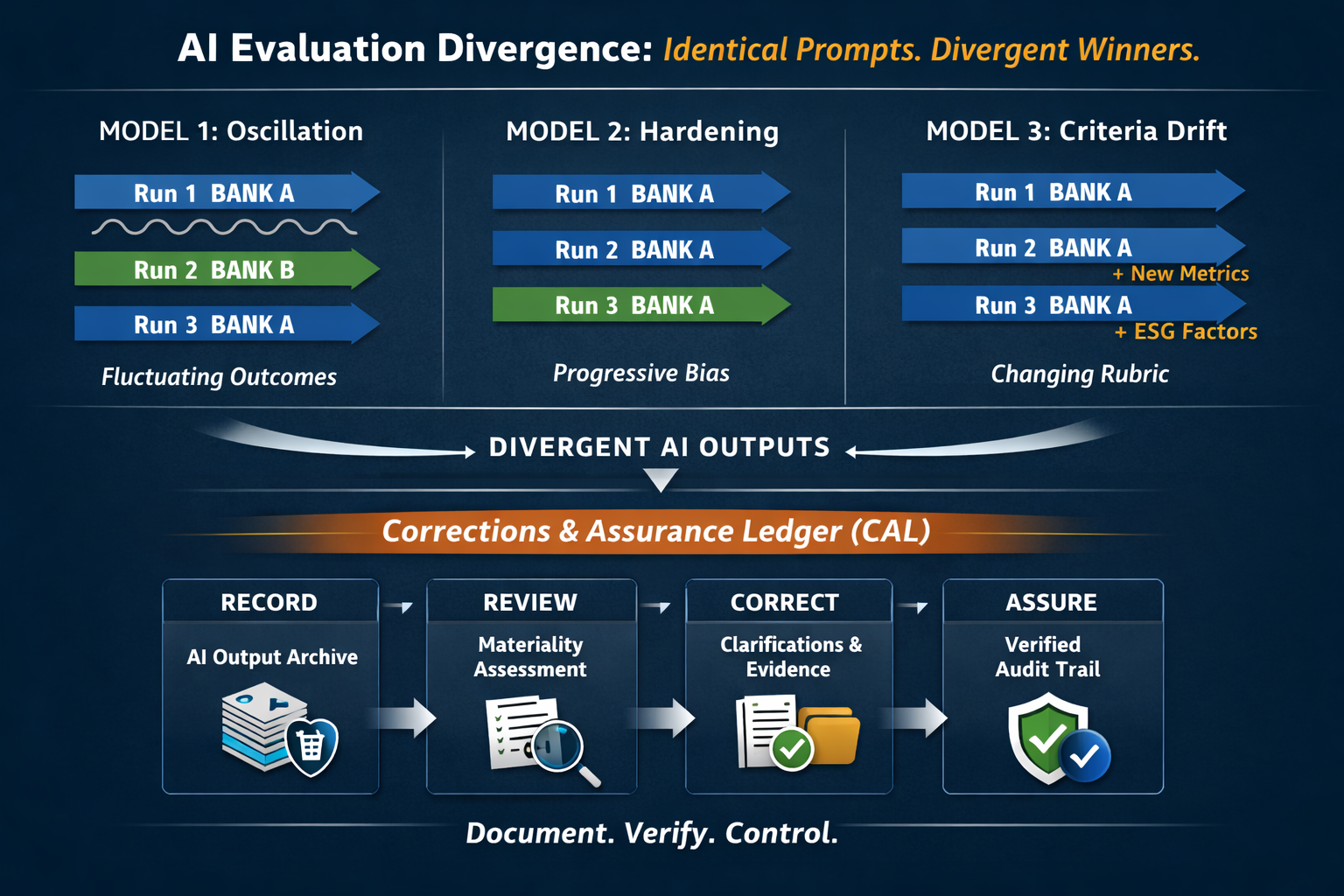
Model 1: Explicit Winner Oscillation
Observed pattern:
- Run 1: Institution A recommended decisively
- Run 2: Institution B recommended
- Run 3: Institution A recommended again
Under identical prompt framing, the model alternated between institutions.
Drift characteristics included:
- Winner flip drift
- Rubric redefinition between runs
- Authority-anchor shift
Severity classification: High.
This reflects recommendation instability within a single system under fixed conditions.
Model 2: Progressive Recommendation Hardening
Observed pattern:
- Run 1: Balanced comparative evaluation
- Run 2: Institution A gains soft preference via authority references
- Run 3: Institution A emerges as default for most SMEs
No winner flip occurred.
However:
- Authority signals accumulated
- Framing shifted from comparative to implied default
Severity classification: Moderate.
The recommendation did not reverse. It tightened.
Model 3: Rubric Expansion Under Stable Tilt
Observed pattern:
- Run 1: Archetype-based comparison
- Run 2: Strategic narrative reinforcement for Institution A
- Run 3: Additional evaluation criteria introduced (e.g., digital capability, ESG positioning)
Winner direction remained consistent.
However:
- Evaluation architecture expanded between runs
- Criteria insertion was not explicitly prompt-driven
Severity classification: Moderate.
No oscillation, but no fixed rubric.
3. Category 8: Personalised Decision Framing
Under personalised scenario framing, a different pattern emerged.
Across multiple premium-tier systems:
- Deterministic reinforcement of one institution across repetitions
- Prescriptive closure language
In at least one system:
- Split optimisation between institutions
This indicates that convergence and divergence coexist across platforms and tiers.
The ecosystem exhibits fragmentation rather than uniform directionality.
4. What the Evidence Demonstrates
This study does not show:
- Universal disadvantage
- Coordinated bias
- Ecosystem-wide targeting
It does show:
- Platform-dependent winner instability
- Identical prompts yielding opposite procurement outcomes
- Run-level drift in evaluation criteria
- Authority accumulation without disclosure
- Structural differences in answer synthesis across systems
The phenomenon is reproducibility-related, not fairness-related.
5. Proportionality and Reliance
The operational significance of these patterns depends on reliance.
If AI-mediated recommendations are only occasionally consulted, observed variance may be informational rather than material.
If such outputs increasingly inform shortlist formation, procurement comparisons, or customer pre-engagement evaluation, visibility into those representations may become strategically relevant.
This framework does not assume materiality.
It provides a structured method to observe and classify externally generated representations should institutions determine that insight into these patterns is valuable.
6. Cross-Model Architecture Differences
The evidence suggests that systems differ in:
- Stability of winner selection
- Tendency toward narrative hardening
- Susceptibility to rubric expansion
- Propensity for persona segmentation
These differences reflect architectural and training variations across models.
They are structural characteristics of probabilistic language systems rather than indicators of coordinated behaviour.
7. Cross-Sector Replication
Parallel scenario testing in healthcare and financial technology contexts demonstrates similar structural patterns:
- Identical prompts yielding divergent outcomes
- Convergence in some models
- Oscillation or drift in others
The observed behaviour appears ecosystem-structural rather than sector-specific.
8. From Visibility to Assurance
Institutions cannot control how external AI systems synthesise recommendations.
They can determine whether to observe, document, and assess those representations.
Evidentia provides structured preservation of externally generated outputs, including:
- Timestamped run capture
- Scenario-class versioning
- Cross-model drift classification
- Historical retrieval capability
Preservation answers the question: What was said, when, and how consistently?
In regulated environments, a second question often follows: How was that representation reviewed, assessed, and—if necessary—corrected?
The Corrections & Assurance Ledger (CAL) provides that layer.
CAL records:
- The preserved external representation
- The institution’s materiality assessment
- Any clarification or correction issued
- Supporting documentation
- Assurance status and version history
Together, Evidentia and CAL convert volatile external AI representations into a managed evidentiary record.
This is not optimisation.
It is structured observation and assurance.
Conclusion
Identical prompts can produce deterministic convergence, progressive hardening, or explicit winner oscillation across leading AI systems.
No universal disadvantage was observed.
No systemic targeting was identified.
Platform-dependent divergence was measurable and reproducible.
As AI-mediated recommendation becomes embedded in procurement research, SME decision-making, and retail comparison behaviour, institutions face a practical strategic question:
Do we have visibility into how external AI systems represent us at the moment comparative choice is resolved?
Where that visibility matters, structured preservation provides insight.
Where defensible oversight is required, assurance documentation provides discipline.
In multi-model environments, the advantage is not forcing convergence.
It is establishing a repeatable cycle of observation, assessment, and evidentiary control.
AI Visibility Intelligence Briefing
This case series documents structural divergence across leading AI systems.
If your institution would like to understand how those systems currently resolve comparative choice in your category, AIVO offers structured AI Visibility Intelligence briefings tailored to regulated sectors.
Begin with clarity.
Determine materiality.
Escalate only if warranted.
Request a confidential AI Visibility Intelligence session: tim@aivostandard.org
