Why Citation Data Cannot Explain AI Decision Exclusion


Abstract
Recent analyses of large-scale citation behavior in conversational AI systems have suggested that visibility within citation graphs offers a proxy for influence and decision relevance. This article explains why that assumption fails in decision-adjacent contexts, and why reliance on citation data creates a false sense of governance control. Drawing on a multi-model evidentiary record of observed external AI behavior, we show that citation presence neither predicts nor explains decision eligibility, authority filtering, or entity substitution. Citation data describes a surface phenomenon. Decision exclusion occurs elsewhere, under different rules, and at later stages of model execution, leaving organisations unable to reconstruct or defend what influenced real decisions.
1. The category error at the heart of citation analysis
Citation studies implicitly treat citations as evidence of sourcing. This is the foundational mistake.
In large language models, citations are not causal inputs in the classical sense. They are a representational layer that may be added, suppressed, or reformatted depending on prompt structure, interface constraints, or policy overlays. The presence of a citation does not demonstrate that a source informed the answer. The absence of a citation does not demonstrate that no authority weighting occurred.
Across repeated observations, three patterns consistently appear:
- Answers converge before any citation layer is rendered.
- Citations are appended after answer stabilisation, serving explanatory rather than evidentiary functions.
- Decision-shaping exclusions occur with no citations displayed at all.
Citation data therefore measures what is shown, not what governs.
2. Visibility is not decision eligibility
Citation analyses are structurally biased toward informational prompts. These prompts ask what something is, how it works, or where to learn more. In such cases, visibility and explanation coincide.
Decision-adjacent prompts are different. They evaluate suitability, trust, eligibility, or risk rather than requesting explanation or definition. In these contexts, models apply internal authority heuristics before explanation is generated.
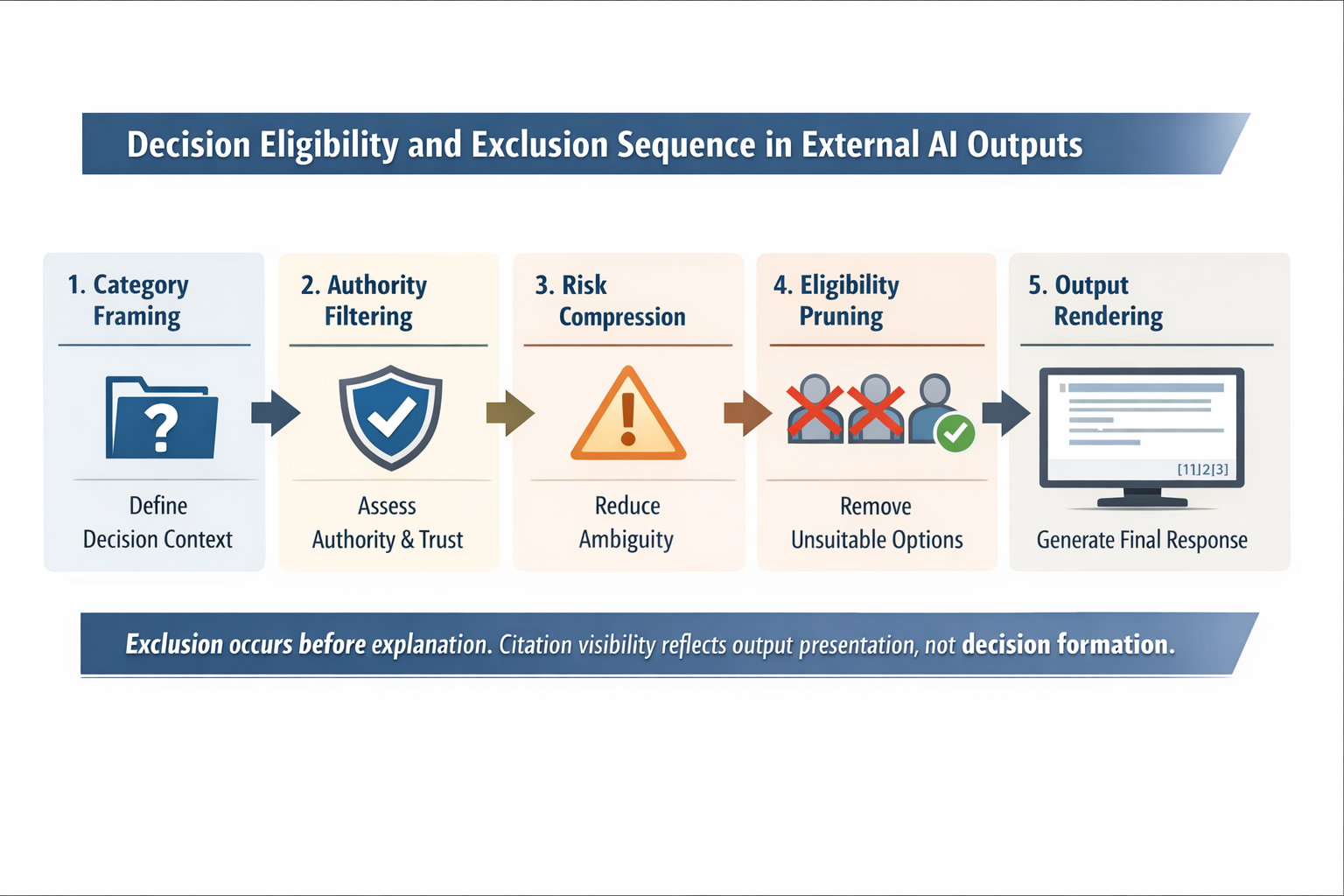
Across repeated inspections, a consistent sequence appears:
- Category framing
- Authority filtering
- Risk compression
- Eligibility pruning
- Output rendering
Citation behavior, when present, appears only at the final stage. Exclusion occurs earlier. Once an entity is removed from eligibility, citation adjacency cannot recover it.
This explains why entities with strong public authority, extensive documentation, and frequent citation presence may still disappear entirely from decision outputs.
3. Early-turn bias masks the exclusion layer
Citation studies often observe that web lookups and citations cluster in the first turn of a conversation. This observation is accurate but incomplete.
Early turns handle orientation. Later turns handle commitment.
Decision exclusion most frequently appears after the model has established framing and narrowed the candidate set. At that point, citations often decline or vanish while authority weighting intensifies.
Studying early turns reveals how models introduce topics. It reveals little about how they finalise decisions.
4. Why optimisation contaminates evidence
Optimisation strategies that pursue citation frequency or adjacency introduce a second failure mode. They interfere with observation itself.
When content is deliberately shaped to influence model outputs, the resulting behavior can no longer be treated as neutral evidence of model operation. The record becomes polluted by intent.
Consider a post-incident review in which a procurement or eligibility decision is challenged. If the organisation has actively optimised content to influence model outputs, it cannot later demonstrate whether:
- the model would have excluded the entity absent intervention,
- the exclusion was stable across time or model versions, or
- the observed output reflected baseline authority heuristics rather than the organisation’s own influence.
In this scenario, temporal integrity is broken, counterfactual comparison is impossible, and forensic defensibility collapses. The organisation cannot separate model behavior from its own intervention.
A system cannot both influence and faithfully observe the same behavior.
5. The governance implication
The core governance problem posed by external AI systems is not accuracy. It is non-reconstructability.
When an AI system excludes an entity, substitutes another, or collapses a category, the affected organisation typically cannot reconstruct:
- what was presented,
- under which conditions,
- at which point in time,
- under which authority assumptions.
Citation datasets do not solve this problem. They describe aggregate visibility patterns. They do not preserve decision-state evidence.
Decisions are made at the eligibility layer. Accountability requires access to that layer. Citations sit above it.
Conclusion
Citation behavior describes how AI systems explain themselves.
Decision exclusion describes how they operate.
Conflating the two obscures risk, contaminates evidence, and delays the development of appropriate governance controls.
The unresolved governance question is no longer who gets cited.
It is who disappears, when, and without a record.
Appendix A: Methods and Observational Basis
The observations described in this article are drawn from a structured, multi-period inspection of externally facing AI system behavior under decision-adjacent prompting conditions.
The inspection program focuses on reproducible output patterns across multiple general-purpose AI systems, evaluated over time and across model and policy updates. Prompts are designed to surface eligibility, trust, and risk evaluation behavior rather than informational explanation.
The record preserves outputs as observed at the time of execution, without optimisation, content shaping, or intervention intended to influence outcomes. The purpose of the record is descriptive, not adversarial, and does not assert internal model mechanisms or training provenance.
No claims in this article rely on access to proprietary system internals. All conclusions are drawn from observable behavior at the interface level.
Governance Note
What Citation Dashboards Cannot Provide in AI Governance
Citation dashboards describe visibility. They do not describe eligibility.
They can show which sources appear frequently, how often citations are displayed, and which domains cluster around certain topics. They cannot show when an entity was evaluated and excluded before explanation occurred.
They cannot reconstruct decision-state conditions.
They cannot separate baseline model behavior from post-hoc explanation layers.
They cannot support counterfactual analysis after an incident.
As a result, citation dashboards are unsuitable as assurance instruments for governance, audit, or dispute resolution. They may inform content strategy. They cannot evidence decision influence.
Using them as governance controls creates a false sense of oversight.