Why Enterprises Need Evidential Control of AI Mediated Decisions

AI systems operated by external providers now influence which vendors are shortlisted, which products appear suitable, which service providers are trusted, and how enterprise capabilities are interpreted by customers and employees. These systems produce compressed judgments, narrow the field of options, introduce substitutions, and produce suitability assessments that alter real decisions. Most organisations use performance monitoring tools to observe outputs or optimise visibility. These approaches do not provide evidential control of how external AI systems construct and apply reasoning.
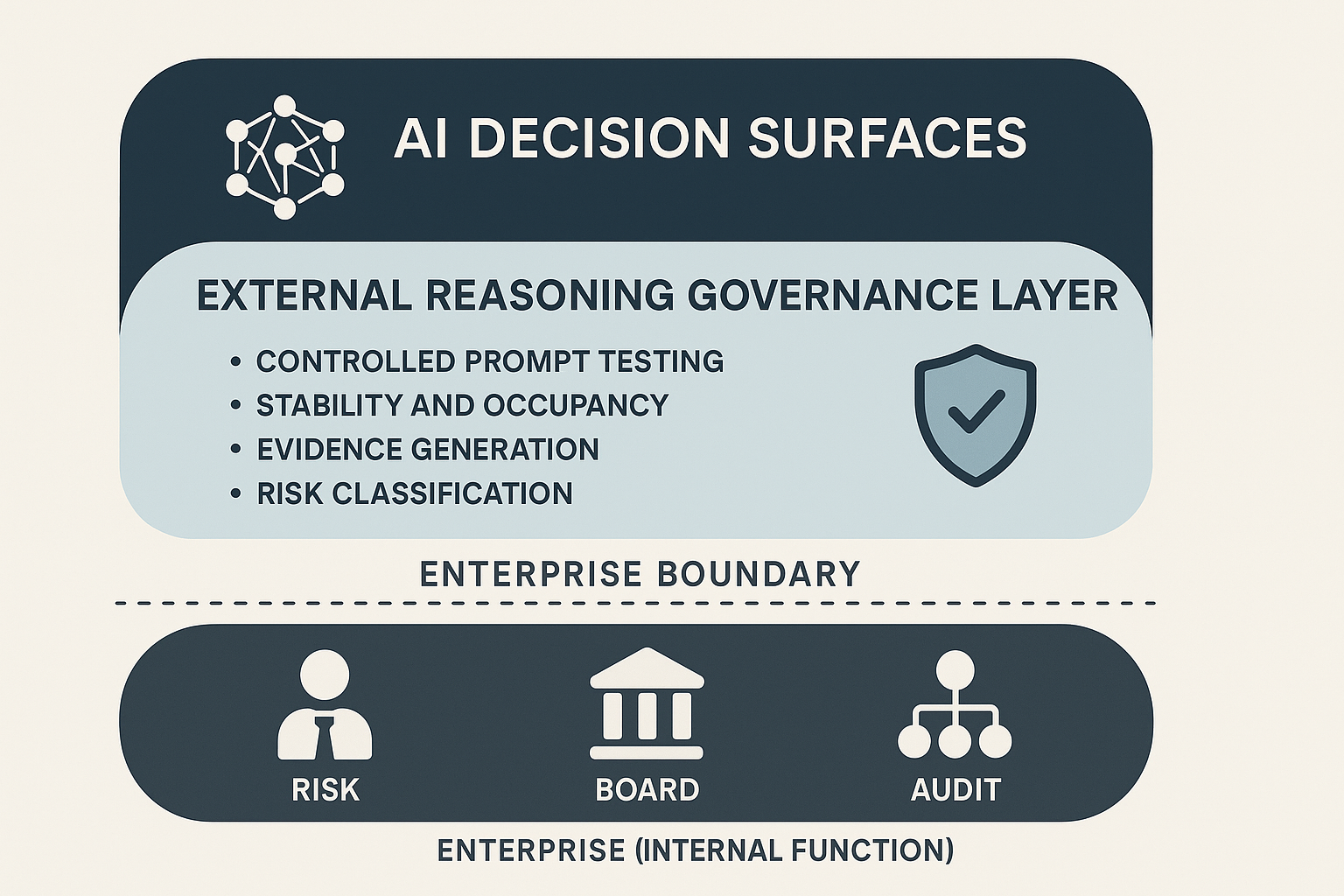
This article defines the external reasoning governance layer, describes the failure modes that create exposure, explains what evidential control requires, and sets out how AIVO implements this control in practice through a reproducible methodology. It also addresses board level implications and integration into enterprise governance structures.
1. The Rise of AI Decision Surfaces
AI assistants now act as reasoning agents rather than retrieval systems. Their outputs resemble judgments rather than lists. They compress information into a small set of options, often between three and five entities, even when many more are relevant. Recent surveys indicate that between forty and sixty percent of enterprise buyers use AI assistants as a first step in vendor research. Internal teams also rely on AI when evaluating suitability or explaining products.
Several shifts are visible:
First. Discovery pathways now pass through compressed answers rather than search listings.
Second. Suitability judgments are produced even when no underlying evaluation criteria are visible to the user.
Third. Substitution occurs when invented or incorrect attributes create a perceived match with another provider.
Fourth. Exclusion occurs when an entity no longer appears in compressed outputs due to model drift or prompt space compression.
Fifth. Multi turn interactions can degrade context or introduce contradictions within the same query sequence.
These surfaces influence procurement, product evaluation, customer research, compliance inquiries, and operational workflows. Enterprises have no control over how these surfaces are constructed or updated.
2. What Makes This a Governance Problem
AI outputs are now a component of enterprise decision making. A procurement analyst comparing platforms, a customer evaluating suitability, or an employee seeking operational guidance all rely on AI mediated judgments.
This raises a governance question:
Can external AI outputs that influence decisions be relied upon, reproduced, and evidenced.
Monitoring tools answer questions about presence, performance, or sentiment. They do not answer governance questions about reasoning integrity.
Boards and risk leaders must consider:
- Are representations accurate.
- Are judgments stable across runs.
- Are competitors substituted due to invented attributes.
- Are we excluded from compressed surfaces.
- Can we produce evidence of how these systems behaved over time.
These are governance issues that require reproducible and auditable evidence. Observational monitoring is insufficient.
3. Defining External Reasoning
External reasoning refers to decisions, judgments, or classifications made by AI systems that are:
- Operated by external vendors.
- Updated without notice.
- Trained on unknown data.
- Influenced by opaque reasoning patterns.
- Applied to enterprise entities without control or oversight.
External reasoning is outside the enterprise boundary yet influences internal decision making. This asymmetry creates a governance responsibility.
4. Failure Modes That Create Material Exposure
Enterprises face six categories of failure that cannot be detected through conventional monitoring.
4.1 Representation Misstatements
These occur when a model invents, omits, or distorts attributes. Examples include incorrect certification claims, false capability statements, or invented regulatory obligations. These shift suitability judgments and introduce operational risk.
4.2 Variance Instability
Repeated tests under identical conditions can produce conflicting answers. This includes changes in vendor ranking, suitability assessments, or risk classifications. Instability can mislead employees, customers, or procurement analysts.
4.3 Prompt Space Occupancy Collapse
An entity may lose presence in compressed answer sets due to internal model shifts. A platform may appear in only twenty or thirty percent of runs, creating inconsistent exposure that is invisible to internal teams.
4.4 Substitution Events
Competitors may be substituted when invented attributes create false parity. Substitution distorts competitive positioning and affects procurement outcomes.
4.5 Single Turn Compression
Decisions often occur in the first output. If an entity is excluded at this stage, it may never enter the decision process.
4.6 Multi Turn Degradation
Representations degrade along interaction pathways. A platform may be described accurately in an initial turn, then misclassified or contradicted in later turns.
These failure modes influence enterprise outcomes and require structured testing to detect.
5. Defining Evidential Control
Evidential control is the ability to produce reliable, reproducible, and auditable evidence of how external AI systems represent and evaluate an enterprise. It requires five conditions.
5.1 Reproducibility
The same prompt executed under controlled conditions must produce results that allow measurement of stability or instability. For example, thirty repeated runs of a prompt may reveal a twenty percent swing in suitability judgments, which is material for governance.
5.2 Attribution Certainty
It must be possible to determine whether a claim is grounded in observable attributes or invented by the model. For example, determining whether a model's statement about "enterprise grade encryption" reflects published documentation or invented content.
5.3 Stability Thresholds
Enterprises need defined variance tolerances. A shift from ten percent to forty percent exclusion is not random noise but a structural change that requires investigation.
5.4 Decision Pathway Evidence
Outputs must be tested across single turn and multi turn interactions. For example, a product may be deemed suitable in initial answers and unsuitable in later turns due to context drift.
5.5 Falsifiability
Evidence must allow an independent reviewer to conclude whether an answer was incorrect or unstable. This requires complete logging, metadata, and integrity controls such as hashing.
These standards distinguish evidential control from observational monitoring.
6. Requirements for Governing External Reasoning
Evidential control requires:
- Standardised prompt sets across key categories.
- Multi run testing to isolate instability.
- Multi model testing for cross vendor divergence.
- Occupancy measurement to detect exclusion.
- Substitution detection across runs.
- Drift measurement to detect reasoning shifts over time.
- Version controlled evidence packages with metadata and integrity checks.
- Clear severity classification.
This creates a structured governance layer distinct from optimisation or performance monitoring.
7. AIVO Methodology in Practice
AIVO implements evidential control through a reproducible methodology defined in the AIVO Standard.
7.1 Controlled Prompt Testing
AIVO builds prompt taxonomies across:
- Product explanations
- Vendor comparisons
- Pricing and packaging
- Regulatory relevance
- Industry specific suitability
Each prompt is run repeatedly under fixed parameters.
7.2 Stability and Occupancy Measurement
AIVO measures:
- PSOS which quantifies presence. It represents the percentage of runs in which an entity appears within a response set.
- ASOS which quantifies reasoning consistency. It reflects how similar the descriptions and judgments are across runs.
- Drift velocity, which measures how quickly reasoning patterns change across cycles.
- Substitution frequency, which identifies how often an entity is replaced.
7.3 Evidence Generation
Each test produces:
- Prompt text
- Model identifier
- Parameters
- Raw responses
- Metadata
- Timestamps
- Hashes for integrity
Evidence is stored in a version controlled structure suitable for audit review.
7.4 Risk Classification
AIVO categorises findings into:
- Low and medium variance
- High severity misstatements
- High severity substitution
- Critical exclusion events
This supports triage and remediation planning.
7.5 Reporting and Governance Flows
AIVO delivers:
- Quarterly governance reports
- Monthly operational briefs
- Audit ready evidence packs
- Cross model divergence reports
- Stability dashboards for risk teams
Reports integrate with existing risk and compliance processes.
8. Anonymised Scenarios Illustrating Real Failure Modes
Scenario 1: Substitution
A competitor appeared in eighty percent of comparative queries because the model invented an ISO certification. The enterprise had no control over this misstatement. Substitution altered procurement outcomes.
Scenario 2: Exclusion
A platform appeared in only twenty eight percent of suitability judgments for mid sized organisations. Internal staff assumed stable representation. Controlled testing revealed systematic exclusion caused by compression effects.
Scenario 3: Divergence
Two major models produced opposite suitability judgments. One consistently recommended the platform. Another consistently rejected it. Divergence was caused by different latent associations unrelated to enterprise attributes.
Scenario 4: Degradation
A product described as compliant in a first turn was described as non compliant in later turns. This affected internal teams using AI tools for regulatory interpretation.
These scenarios reflect patterns observed across multiple enterprises.
9. Enterprise Integration and Ownership
9.1 Ownership
Common owners are:
- Chief Risk Officer
- Chief Compliance Officer
- Enterprise Architecture
- Internal Audit
9.2 RACI
- Risk: accountable
- Audit: reviewer
- Architecture: technical support
- Product and commercial teams: informed
9.3 Cadence
- Quarterly governance reporting
- Monthly instability briefs
- Annual evidence reviews
- Ad hoc testing after major model updates
9.4 Implementation Scope and Effort
Typical implementation spans four to eight weeks and requires approximately forty to eighty hours of internal effort across teams.
- Week 1: scoping and taxonomy design
- Week 2: prompt development and calibration
- Weeks 3 to 4: test execution and variance analysis
- Weeks 5 to 8: governance integration and reporting setup
10. Alternatives and Their Limitations
Enterprises typically use four approaches.
Brand Monitoring
Captures mentions and sentiment but does not evaluate reasoning stability or suitability accuracy.
Optimisation Tools
Improve visibility but do not test whether reasoning is stable or correct.
Ad Hoc Testing
Provides snapshots but no reproducible evidence.
Do Nothing
Leaves the enterprise exposed to misrepresentation and instability.
None of these approaches provide evidential control.
11. Board and Regulatory Implications
AI mediated decision surfaces affect:
- Revenue
- Procurement outcomes
- Compliance interpretations
- Customer trust
- Employee decision making
Boards should ask:
- Are representations correct.
- Are judgments stable.
- Are we being substituted.
- Are we excluded.
- Can we evidence results.
Regulators in several jurisdictions have signalled that organisations must demonstrate accountability for AI influenced decisions. The EU AI Act and recent supervisory guidance in financial services highlight the need for documented oversight and risk controls for AI assisted processes.
12. What AIVO Does and Does Not Do
AIVO operates in the external reasoning governance layer.
AIVO does:
- Test accuracy and stability
- Detect exclusion and substitution
- Generate evidence
- Provide governance reports
- Support audit reviews
- Manage cross model divergence
AIVO does not:
- Optimise prompts
- Improve ranking or visibility
- Tune content
- Operate within the model loop
- Provide performance dashboards
This clarifies the distinction between governance and monitoring functions.
Conclusion
External AI systems shape decisions that affect enterprise outcomes. These systems compress information, shift reasoning patterns, substitute entities, and degrade across interaction pathways. Monitoring tools observe outputs but cannot determine whether such outputs can be relied upon. Evidential control is required for decision integrity.
The external reasoning governance layer provides a structured, reproducible, and auditable way to measure how AI systems represent and evaluate an enterprise. AIVO implements this layer through controlled testing, stability measurement, failure mode detection, and evidence generation suitable for governance, audit, and regulatory use.
Organisations should assess their exposure by considering:
- Whether employees, customers, or procurement teams rely on AI mediated discovery.
- Whether external AI systems have produced inconsistent or concerning outputs.
- Whether the enterprise can provide evidence of representation accuracy and stability.
If the answer is uncertain, external reasoning governance warrants evaluation. Evidential control is no longer optional. It is a structural requirement for organisations that rely on or are evaluated by external AI systems.
