The AIVO Paradox

Why the brand you can see in AI is not the brand that wins the sale
Every week, brands across the world pay for tools that tell them how often AI mentions them. Share of voice. Citation frequency. Mention rates. The dashboard updates. The numbers go up. The quarterly report looks good.
And in the background, a competitor is taking the buying recommendation. Every time.
This is the AIVO Paradox. It is not a hypothesis. It is the most consistent finding in our two-year probe corpus spanning 137+ brands, five major categories, and five AI platforms. Nineteen of every twenty brands we test have a 0% win rate at the AI purchase recommendation stage despite measurable, sometimes strong, AI visibility scores.
The paradox is not about brands being bad at AI. It is about a fundamental measurement problem that the industry has not yet confronted directly. The tools built to measure AI brand performance are measuring the wrong thing.
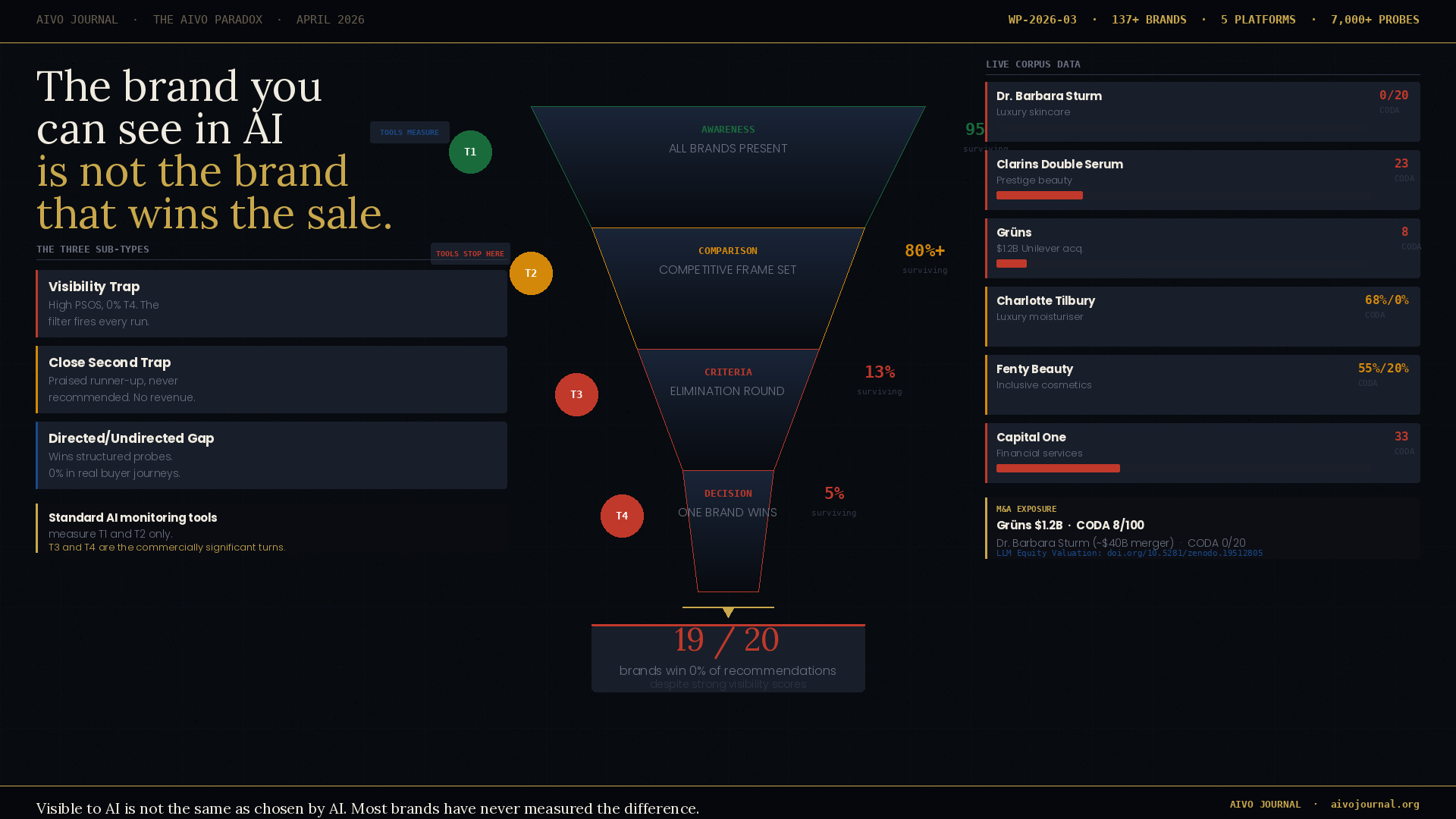
19 of every 20 brands we test have a 0% AI purchase recommendation win rate despite measurable AI visibility.
The gap the dashboards don’t show
When a consumer opens ChatGPT and searches for the best moisturiser, the best supplement, or the best HR platform, they are not asking one question. They are having a conversation. That conversation moves through distinct stages.
They start broad. What are the best options in this category? Most brands with any meaningful market presence appear here. This is what AI visibility tools measure. It is the awareness layer, and it matters — but it is not where the buying decision is made.
They get specific. How do these options compare? What should I prioritise? This is where the competitive frame narrows and where most brands begin to lose ground without knowing it.
They decide. Just tell me what to buy. This is Turn 4. This is where revenue is determined. This is the only turn that matters commercially — and it is the turn that no standard AI monitoring tool currently measures.
The AIVO Paradox is the gap between how a brand performs at Turn 1 and how it performs at Turn 4. In the majority of cases, that gap is enormous.
What the data shows
We have run over 7,000 structured buying sequence probes across ChatGPT, Perplexity, Gemini, Grok, and Claude. The pattern is consistent across every category we have tested.
|
Brand |
Visibility |
CODA T4 Win
Rate |
Finding |
|
Dr. Barbara
Sturm |
High |
0 / 20 runs |
Present
everywhere. Wins nothing. |
|
Clarins
Double Serum |
High |
23 / 100 |
Category
leader. Eliminated at T4. |
|
Grüns
(wellness) |
Moderate |
8 / 100 |
$1.2B
acquisition. Eliminated. |
|
Charlotte
Tilbury |
59/100 |
68% directed
/ 0% undirected |
Wins
structured probes. Fails real journeys. |
|
Fenty Beauty |
High |
55% ChatGPT /
20% Perplexity |
Coined the
terminology. Lost the inference. |
|
Capital One |
#1 category |
33 / 100 |
Most-mentioned.
Loses T4 on both platforms. |
Each of these brands scores well on the metrics their teams are currently tracking. The buying recommendation tells a different story.
Three ways the paradox manifests
The AIVO Paradox is not a single mechanism. Across our corpus we have identified three distinct sub-types, each with a different cause and a different remediation path.
The Visibility Trap. The brand is deeply embedded in AI training data but fails the T3 criteria filter on every run. Dr. Barbara Sturm: present in the competitive set of every model, every run, zero T4 wins across 20 independent probe sequences. The brand’s anti-inflammatory, retinoid-free positioning is precisely the clinical evidence gap that every model identifies and penalises.
The Close Second Trap. The brand reaches T4 as a praised runner-up but never wins. It generates AI-assisted consideration without conversion — awareness cost with no revenue return. The acknowledgement is warm. The recommendation goes elsewhere. Capital One and Augustinus Bader both operate here.
The Directed/Undirected Divergence. The brand performs well in structured probe conditions and achieves 0% purchase conversion in undirected conditions that replicate real consumer behaviour. Charlotte Tilbury on Gemini: 80% CODA win rate, model withdrawal and no recommendation under the undirected Journey Probe. The structured measurement was producing a result that real-world behaviour systematically contradicts.
The brand is not told it is wrong. It is told it is excellent, but for a slightly different purpose. The recommendation goes elsewhere.
The M&A implication
The commercial consequences extend beyond marketing strategy. Two acquisitions in the past month illustrate the scale of the exposure.
Unilever paid $1.2 billion for Grüns. CODA score the morning of the announcement: 8/100. Eliminated before the final AI recommendation on both ChatGPT and Perplexity across every sequence tested.
The Puig/Estée Lauder merger — approximately $40 billion — includes Dr. Barbara Sturm. CODA score: 0/20. One of the highest-awareness luxury skincare brands in our corpus. Zero buying recommendations.
We have published a methodology for quantifying this gap as a valuation metric: LLM Equity Valuation (LEV™). Category TAM multiplied by AI purchase influence rate multiplied by T4 win rate. For Grüns: $8B × 0.29 × 0.08 = approximately $186M LLM Equity against a $1.2B acquisition price. The AI channel gap at the moment of transaction was roughly $1 billion. This figure is currently absent from every acquisition due diligence framework we have reviewed.
What moves the needle at T4
Three structural patterns emerge consistently from the remediation data:
Evidence architecture, not content volume. Brands eliminated by the clinical evidence binary require independently peer-reviewed publication on their core mechanisms. Not more owned content. Peer review. The absence is the specific signal the model is responding to, and the only intervention that changes it is its presence.
Third-party encoding, not brand voice. The inference attribution failure mode — where a brand coins terminology but loses the recommendation because a competitor’s evidence is more deeply encoded — is not solvable by improving owned content. Editorial coverage, independent review, comparative testing generate the corpus signals that move T4 outcomes.
Platform-specific strategy, not category-level optimisation. Different platforms apply different evaluative standards at T4. The platform epistemology split — ChatGPT and Grok producing perfectly inverse T4 outcomes for Augustinus Bader — means remediation requires platform-specific interventions targeting the evidence standards each model applies.
The measurement the industry needs
The AIVO Paradox is a measurement problem before it is a strategy problem. Brands cannot fix a gap they cannot see. The industry has built excellent tools for measuring AI visibility. It has not yet built the tools for measuring AI recommendation outcomes — and the two measurements diverge systematically and materially.
The question is not whether the AIVO Paradox exists. The data is unambiguous. The question is how long the industry takes to build measurement infrastructure that reaches the layer where buying decisions are actually made.
Working Paper WP-2026-03 available open access on Zenodo:10.5281/zenodo.19568058 . Related: WP-2026-01 (CODA, doi.org/10.5281/zenodo.19401584) and WP-2026-02 (LEV™, doi.org/10.5281/zenodo.19512805).
Run the diagnostic on your brand: aivooptimize.com · Free · 60 seconds