Introducing AIVO Optimize: The Self-Serve Decision-Stage Diagnostic for AI Visibility

AIVO Journal | Product | May 2026
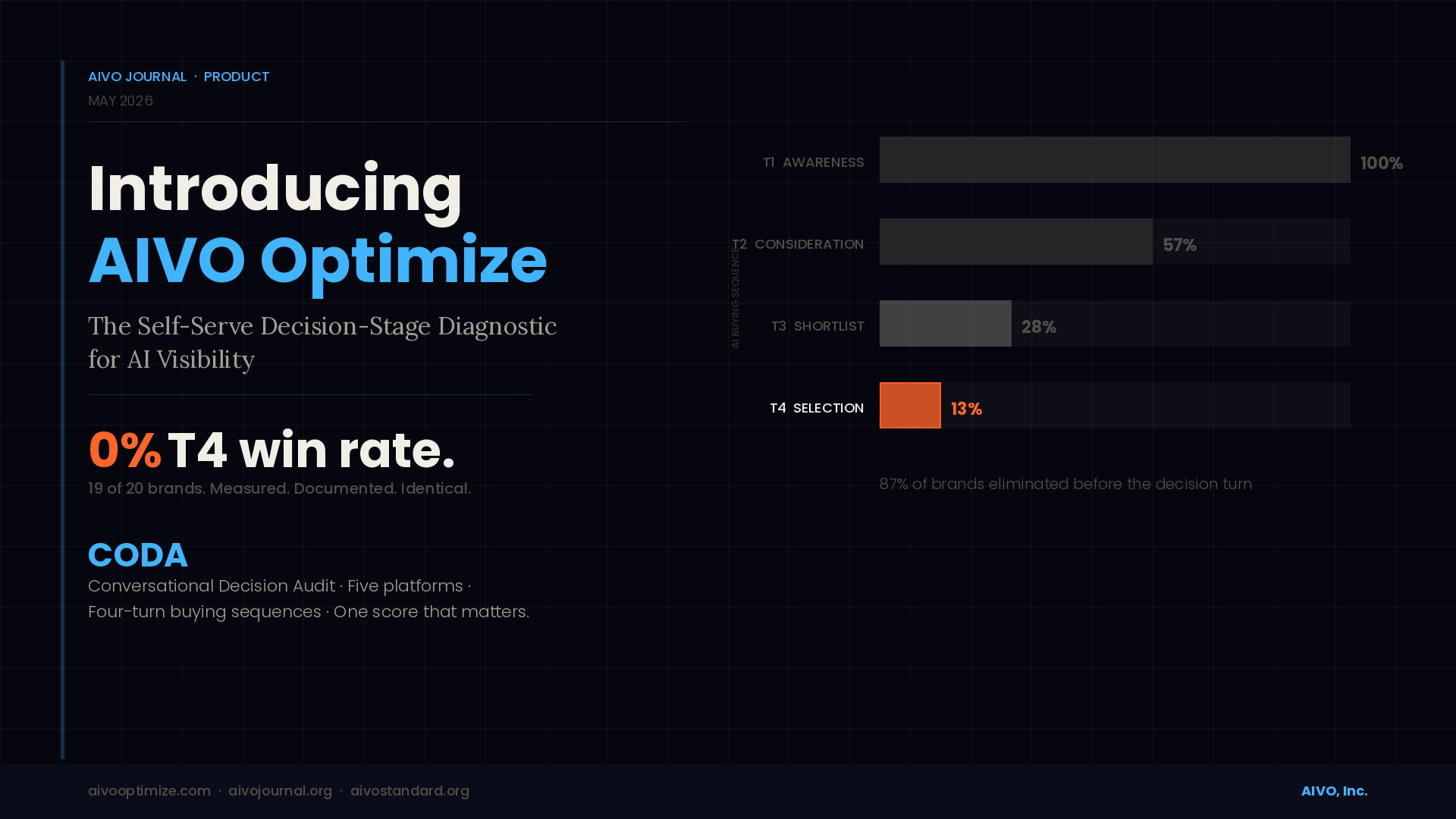
Nineteen of the twenty brands in our first published decision-stage audit had a T4 win rate of zero. Not low. Zero. Every one of those brands had invested in AI visibility. Most scored reasonably well on citation frequency. Some appeared in hundreds of AI responses per month. None of it converted to a buying recommendation when the consumer was ready to decide.
That is the problem AIVO Optimize was built to solve.
The Measurement Gap No One Was Naming
The AI marketing measurement market grew fast. Platforms emerged to count citations, track mention share, and benchmark "brand visibility" across large language models. The category had a name before it had a methodology. And the methodology, when it arrived, was built around the wrong question.
The right question is not "does AI mention my brand." The right question is "does AI select my brand when a consumer is ready to buy."
Those two questions produce different answers for the same brand in the same week. Charlotte Tilbury generates a directed CODA score of 68 on Gemini. On undirected journey probes, the same platform, the same brand, the same period, the score is zero. The brand appears when asked about. It disappears when not asked about. That divergence is not a data artifact. It is the fundamental measurement problem of the AI decision layer.
Existing platforms were not built to detect it. AIVO Optimize was.
What CODA Measures
AIVO Optimize runs on CODA: the Conversational Decision Audit. CODA is not a visibility score. It is a decision-stage score. It measures whether a brand survives the complete arc of a consumer buying sequence and emerges as the final recommendation.
The methodology uses four-turn conversational probes that mirror real consumer behavior. Turn one establishes category need. Turn two narrows to product type. Turn three surfaces shortlist criteria. Turn four asks the AI to decide. CODA is calculated at T4. Everything upstream is diagnostic context, not the score.
This structure matters because AI models do not behave like search engines. They compress. They eliminate. Across 7,000 buying sequences in our baseline dataset, 87% of brands were eliminated before turn four. A brand with strong T1 and T2 presence can have a T4 win rate of zero. Gucci does. Measured across undirected luxury purchase sequences, Gucci achieves 100% AI visibility and 0% T4 conversion. High visibility, zero selection. CODA separates those two numbers. No other commercial platform does.
Five Platforms, One Score
AIVO Optimize runs probes across five platforms: ChatGPT, Perplexity, Gemini, Grok, and Claude. The platform split is not cosmetic. Brands behave differently across models in ways that are commercially significant and operationally invisible without platform-level measurement.
Augustinus Bader scores zero out of five on ChatGPT buying sequences and five out of five on Grok. That is not noise. That is a platform-specific recommendation signal that requires platform-specific remediation. A single aggregate score would obscure it entirely.
AIVO Optimize returns a per-platform CODA score and a composite score. The composite is the headline. The per-platform breakdown is where the diagnostic work begins.
The Self-Serve Model
AIVO Optimize is the entry point into the AIVO product stack. It is structured for brand teams and agency practitioners who need decision-stage data without a managed service engagement.
A brand submits its core details through the Optimize interface at aivooptimize.com. The platform runs a full CODA diagnostic across all five AI models, covering category-level buying sequences, direct brand queries, and competitive displacement probes. Results return within five to seven business days. The output includes a CODA score, a platform breakdown, a competitive displacement map, and a prioritised remediation summary.
The tool requires no integration, no implementation overhead, and no prior AI measurement experience. It was designed to answer one question immediately: where does this brand stand in the AI buying sequence today.
What Competitors Measure Instead
Profound, Evertune, PEEC, and AthenaHQ each operate in the AI brand measurement space. Each has made a different version of the same architectural choice: they measure the top of the AI funnel. They count citations, track sentiment, benchmark share of voice. The metrics are real. The problem is what they do not measure.
None of these platforms segments measurement by purchase stage. None uses four-turn structured sequences to simulate the buying arc. None publishes a T4 conversion metric. The result is a category of measurement products that tell brands whether AI knows about them, not whether AI recommends them.
The practical consequence is substantial. A brand acting on citation data alone is optimising for a metric that does not predict purchase influence. AIVO Optimize uses a different KPI because the purchasing decision happens at a different point in the conversation.
Where Optimize Sits in the Stack
AIVO Optimize is the diagnostic layer. It produces the baseline CODA score against which all subsequent optimisation is measured. For brands that need active remediation, AIVO Edge delivers managed implementation. For agency teams managing multiple brand diagnostics simultaneously, AIVO Meridian provides the multi-brand orchestration layer. For governance and compliance documentation, AIVO Evidentia records the attribution chain.
Optimize is where every brand engagement begins. It establishes what is true before any intervention. That baseline is what makes the subsequent work measurable.
The Standard Behind the Score
AIVO Optimize is built on the AIVO Standard methodology, published and peer-reviewed via Zenodo as WP-2026-01. The CODA framework is documented in the same deposit. The brand.context JSON-LD standard (WP-2026-04, DOI: 10.5281/zenodo.19588522) defines how structured brand signals are made legible to AI decision layers, and is the primary technical specification informing Optimize's diagnostic output and remediation guidance.
The methodology is public. The scoring is reproducible. The DOIs are citable. That transparency is deliberate. In a measurement market where methodology disclosure is rare, auditability is a competitive position.
The Publication Gap This Closes
Every other AIVO product has a canonical introduction record: AIVO Edge published February 2026, AIVO Meridian published April 2026, AIVO Evidentia and the brand.context standard published April 2026. AIVO Optimize has existed since the platform's commercial launch and has appeared in case studies, outreach data, and competitive analysis. This article closes that record.
AIVO Optimize is available at aivooptimize.com. Pricing and tier details are on the product page. Diagnostic requests open immediately.
AIVO Journal publishes primary research and product documentation from AIVO, Inc. Methodology papers supporting this article are deposited at Zenodo. DOIs available on request.
Related: WP-2026-01 (CODA Methodology) | WP-2026-02 (LLM Equity Framework) | WP-2026-04 (brand.context Standard) | WP-2026-06 (AIVO Orbit)