Why the AI Visibility Category Is Solving the Wrong Problem

The measurement conversation in AI search has stalled at the wrong question. And the budget consequences of that are about to become visible.
Over the past eighteen months, a category of platforms has emerged to help brands understand their position in AI-generated responses. Citation volume. Mention rate. Share of voice across prompts. These platforms have attracted serious investment, built genuinely impressive interfaces, and established themselves as the default infrastructure for what the industry now calls GEO — Generative Engine Optimisation — and AEO, Answer Engine Optimisation.
The problem is not the interface. The problem is the layer.
Two layers. One matters for purchase.
AI systems do not retrieve evidence from a single source. They operate across two structurally distinct evidence layers, and the distinction between them determines everything about how a brand performs at the moment a consumer makes a purchase decision.
The first layer is the community and editorial retrieval layer. This is where AI draws on indexed web content, editorial sources, forum discussions, retail listings, and recent publications. It is the layer that determines whether your brand appears in a response to a general query. It is also the layer that every major GEO and AEO platform is built to optimise. The content recommendations these platforms generate, and in many cases auto-produce, are designed to improve performance at this layer.
The second layer is the knowledge graph entity layer. This is where the AI has already formed a representation of your brand: in trained model weights, in Wikidata entity definitions, in Wikipedia category statements, and in the structured evidence architecture that the model applies when filtering options at the decision stage of a buying conversation. This layer is not refreshed by web indexing. It is not updated by publishing a new editorial piece or saturating a retail listing. It operates independently of the first layer, on a different cadence, through a different mechanism.
These two layers are structurally independent. Improvements in the first layer do not propagate to the second. In documented cases, content produced by GEO programmes actively conflicts with legacy knowledge graph anchors, producing a pattern that AIVO has now observed consistently across 195 brands: improved first-prompt visibility combined with unchanged or degraded decision-stage recommendation performance.
What actually happens in a buying conversation
A consumer using ChatGPT, Perplexity or Gemini to make a purchase decision is not asking one question. They are running a conversation. Four turns. Six turns. Eight turns. From initial need to final recommendation.
At each turn, the AI is doing something specific. It is applying criteria filters derived from its trained representation of the category. It is evaluating brands against those criteria. It is eliminating options that do not meet the filter threshold. By turn four, in a typical buying sequence, one brand receives the purchase recommendation. The others are gone.
This is the turn that matters commercially. And it is the turn that first-turn visibility metrics cannot see.
The brands doing the displacing at turn four are identifiable. The criteria filters they are winning on are documentable. In five brand case studies published in AIVO's Layer Mismatch paper, covering B2B SaaS, cloud infrastructure, prestige beauty, luxury fragrance and European travel, the displacement mechanism in every case operated at the knowledge graph layer. Not at the retrieval layer. Not at the layer the GEO content programmes were addressing.
Two of those five brands were named customers of the leading GEO platforms. Their visibility scores were strong. Their purchase recommendation performance was not.
Why the category cannot fix this
The layer mismatch is not a product gap that the existing platforms can close with a feature update. It is a structural consequence of what these platforms were built to measure and what they were built to optimise.
Citation rate is a retrieval-layer metric. Share of voice is a retrieval-layer metric. The optimisation content these platforms generate, blog posts, editorial placements, forum seeding, product page enrichment, operates at the retrieval layer. The measurement feedback loop that tells a brand whether its optimisation programme is working is built on retrieval-layer signals.
The knowledge graph entity layer requires different inputs. Wikipedia and Wikidata architecture. Canonical entity definition. Named-institution performance backing. Structured evidence that the trained model can evaluate against its criteria taxonomy. These are not content marketing outputs. They are evidence architecture interventions. They require a different methodology to identify, a different production process to create, and a different measurement instrument to verify.
This is not a criticism of what the existing platforms do. It is a precise description of where they stop.
Why this matters more now than six months ago
ChatGPT is running ads. Buying agents are in development across every major platform. The conversion moment in AI, the turn at which a consumer moves from consideration to purchase, is about to attract serious budget.
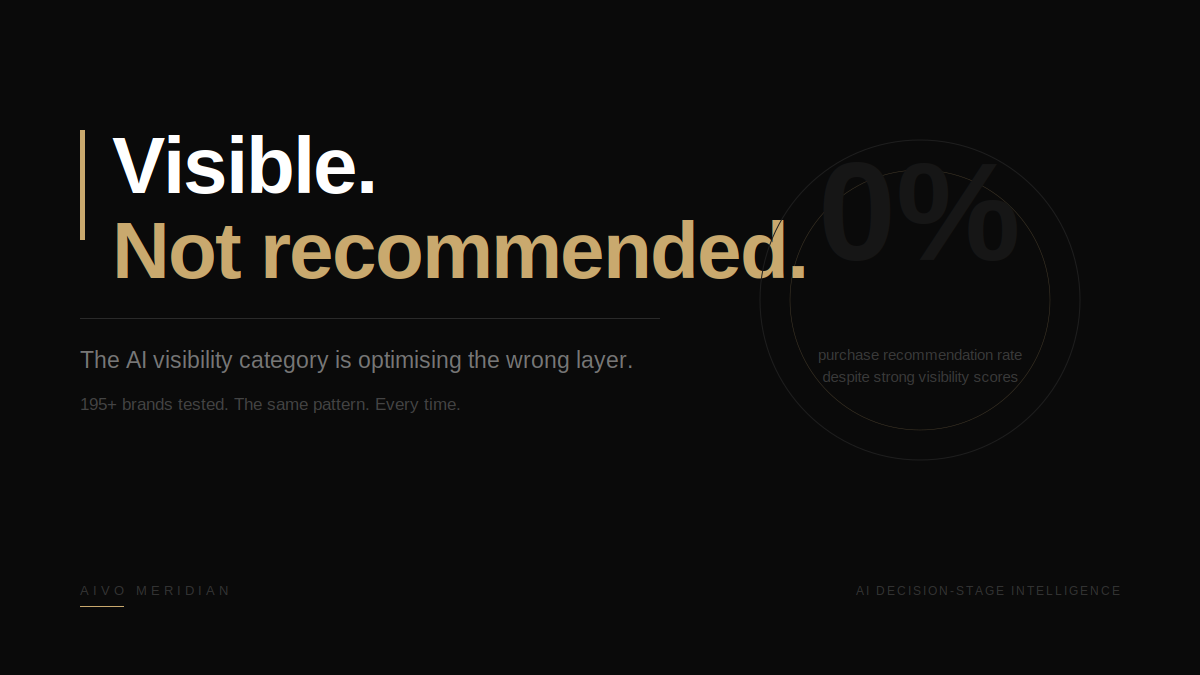
Brands entering that environment without knowing their decision-stage position are buying placements in a funnel they have never measured. A brand with a strong visibility score and a zero per cent purchase recommendation rate on generic probes is not a well-positioned brand with an advertising opportunity. It is a brand being displaced before the ad can reach a consumer who is ready to buy.
Across 195 brands tested by AIVO, the pattern is consistent. Strong visibility scores. Weak purchase recommendation performance. The gap is not a visibility problem. It is an evidence architecture problem.
What actionable looks like
Closing the gap requires three things the existing measurement infrastructure does not currently provide.
First, multi-turn probe data. Not what the AI says about your brand in response to a general query. What happens to your brand across a full buying conversation, turn by turn, from awareness to commercial handoff.
Second, displacement classification. Not that your brand was absent. Which brand displaced it, at which turn, through which criteria filter, and what evidence architecture that competitor holds that yours does not.
Third, evidence gap remediation structured for the knowledge graph layer. Technical interventions that establish entity recognition. Authority content that backs performance claims with citable third-party evidence. Comparative documentation that positions the brand across all four decision axes simultaneously. Deployed in the format and through the channels that trained models and live retrieval systems can process and weight.
This is the programme that closes the chain. Not a better dashboard. Not more content. The right evidence, in the right layer, verified by re-probing at the turn that matters.
The brands that understand this before the buying agent environment matures will hold positions that are structurally difficult to displace. The brands that are still optimising the retrieval layer when agentic purchasing scales will be optimising the wrong thing at the wrong time.
The chain breaks at the same place every time. The question is whether you know where that is before the budget lands.
AIVO Meridian measures brand performance at the AI decision stage across ChatGPT, Gemini, Perplexity and Grok. The Layer Mismatch paper, including five brand case studies with live probe data, is published on Zenodo: DOI 10.5281/zenodo.19840293.