The Layer Mismatch: Why Your GEO Investment May Be Solving the Wrong Problem

A peer-archived study of five major brands reveals a structural gap between AI visibility and AI purchase recommendation outcomes
The GEO and AEO category was founded on a correct insight. Traditional search metrics don't measure brand performance in AI-generated responses. Citation frequency, share of AI voice, and first-prompt visibility are genuinely different signals that require different measurement approaches. Hundreds of millions of dollars have been raised to build tooling around these signals. That achievement is real.
This is the argument of a working paper we published today: the category has accurately solved one measurement problem while creating another.
The measurement brands believe they're purchasing versus what they're getting
When a brand invests in GEO visibility improvement, the commercial outcome it believes it's purchasing is AI purchase recommendation performance — the probability that when a buyer uses ChatGPT, Gemini, or Perplexity to make a decision, the brand wins the final recommendation.
That is not what GEO platforms measure or improve.
AIVO has been measuring decision-stage recommendation outcomes since early 2025 using the CODA four-turn buying sequence protocol. We run structured four-turn buying sequences — mimicking the complete path a buyer takes from initial awareness through comparison, criteria evaluation, and final recommendation — across ChatGPT, Gemini, Perplexity, and Grok. The finding from 195+ brands and 7,000+ buying sequences is consistent: first-prompt citation frequency does not predict decision-stage recommendation outcomes.
A brand can appear in AI responses consistently and comprehensively while recording zero purchase recommendation wins at the decision stage.
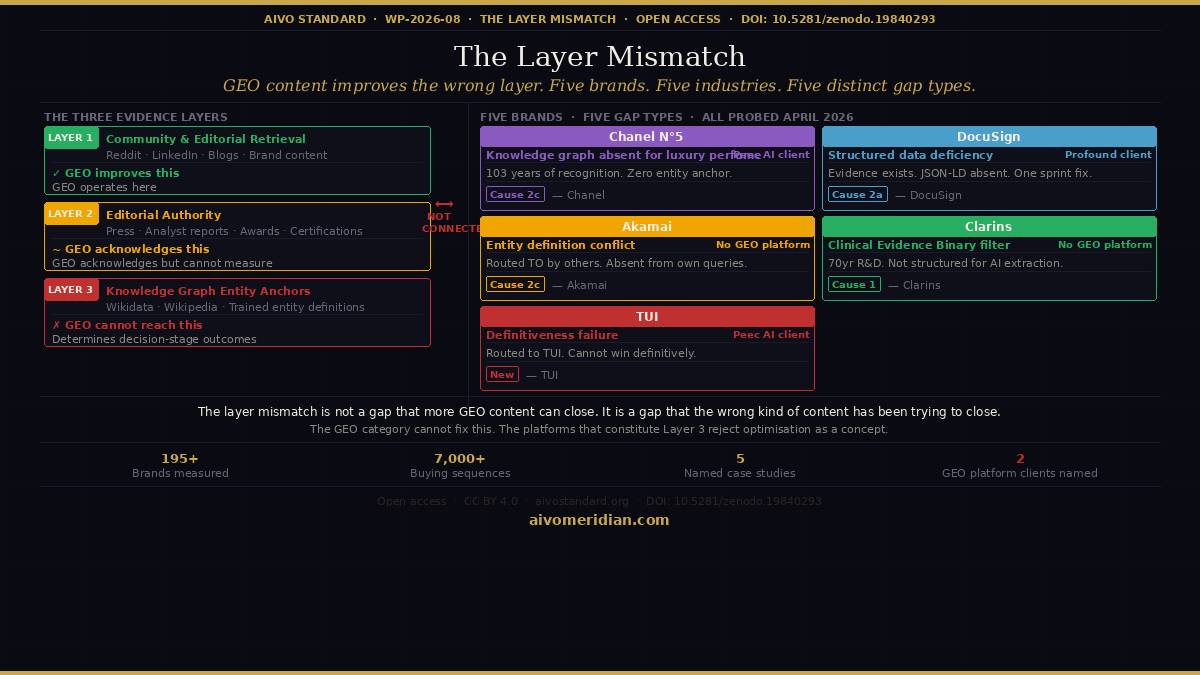
Why: the three evidence layers
AI models use different evidence sources for different cognitive tasks within the same buying conversation.
Layer 1 — Community and editorial retrieval. At the first prompt, the model draws on the most recent, most cited, most accessible content: Reddit threads, LinkedIn posts, YouTube content, blog articles, editorial coverage. This is the layer GEO content programmes are designed to populate. It is also the most volatile layer — Profound's own published research has documented that up to 90% of cited sources in AI answers change over time.
Layer 2 — Editorial authority. Tier 1 press coverage, analyst reports from Gartner and Forrester, industry awards and certifications. GEO platforms acknowledge this layer and recommend pursuing it through PR and earned media. They do not provide structured tooling for measuring whether Layer 2 evidence is satisfying the specific criteria filters the model applies at Turn 3.
Layer 3 — Knowledge graph entity anchors. Wikidata entity definitions, Wikipedia category statements, trained-model entity representations built from historically consistent evidence. This is the layer the model uses when it applies a criteria filter at Turn 3 — asking which brand has established entity recognition in a specific category, which brand has documented clinical efficacy, which brand is the definitive leader in a market segment. It is the most stable layer and the most determinative of decision-stage outcomes. It is also the layer the GEO category cannot address.
These three layers are structurally independent. Layer 1 content does not propagate to Layer 3. In some cases, as the paper documents, it actively conflicts with it.
The five cases
The paper documents five brand case studies, each with AIVO Meridian probe data. Two are named clients of leading GEO platforms. Three are not. The finding is consistent across all five.
Chanel N°5 (Peec AI client). Possibly the most culturally recognised fragrance product in the world, in continuous production since 1921. The AIVO Meridian probe produced five filter gaps. The Gemini T0 finding: "Brand lacks Wikipedia/Wikidata anchor or comparable knowledge graph presence for luxury perfume category." 103 years of cultural recognition have not produced the specific structured entity representation that Gemini's evaluation architecture requires. The ChatGPT finding is equally striking: the model routes buyers from N°5 to Coco Mademoiselle — a sibling product within the same brand family — because Coco Mademoiselle's evidence architecture satisfies the model's four-axis evaluation criteria (effectiveness, value, reputation, accessibility) more completely. The Close Second Trap operating within a single brand's portfolio. Chanel is paying for Peec AI visibility monitoring. Peec AI is reporting how often Chanel N°5 appears. It is not reporting that the brand lacks a correctly structured knowledge graph anchor for the category it has defined for a century.
DocuSign (Profound client). The primary eSignature product page carries no JSON-LD structured data. The FAQ content covering legal enforceability, ESIGN Act compliance, PKI architecture, and SOC 2 Type II certification is rendered as human-readable HTML but is not declared in machine-readable format. The evidence exists. It is not structured in a form the model can reliably extract, attribute, and evaluate at Turn 3. This is a deficiency closeable in a single engineering sprint. It has persisted because GEO tooling is content-shaped rather than infrastructure-shaped, and does not surface infrastructure gaps. DocuSign is investing in Profound's content agents while a Layer 3 deficiency the platform cannot detect remains open.
Akamai Technologies (no GEO platform relationship). Akamai has executed a multi-year brand repositioning from CDN and edge delivery to distributed cloud computing and AI inference infrastructure. The website content is accurate and well-structured. The problem is at the knowledge graph layer: Wikidata entity Q56338 continues to categorise Akamai primarily as a content delivery network company, reflecting 25 years of consistent historical evidence. The probe paradox: other brands being evaluated in the distributed compute category are displaced with the recommendation "Routed to: Akamai Technologies." The model routes other brands' buyers to Akamai. But when a buyer starts fresh with a generic distributed compute query, Akamai does not appear — because the entity anchor does not map to that category. Producing more content positioning Akamai in distributed cloud creates entity definition conflict with the Layer 3 anchor rather than resolving it.
Clarins (no GEO platform relationship). A prestige French beauty brand with 70 years of formulation research. The probe documents displacement at Turn 3 driven by the Clinical Evidence Binary filter — the model asks which brand has documented ingredient efficacy and clinical validation in a format it can extract. CeraVe dominates this filter because its entire brand identity is built around dermatologist-developed clinical evidence published in AI-extractable formats. Clarins' brand identity is built around luxury, heritage, and plant-based science. A GEO content programme would recommend Reddit skincare content, LinkedIn beauty editorial, and blog articles. None of that produces the structured clinical evidence architecture that satisfies the T3 filter. The remediation requires publishing clinical validation data in structured, citable, AI-extractable formats — a Layer 3 intervention that no GEO platform provides.
TUI (Peec AI client). The probe introduces a gap type that none of the preceding cases fully illustrates. The model routes buyers to TUI across multiple turns. TUI is not being displaced by competitors in the traditional sense. The problem is that TUI cannot convert that routing into a definitive recommendation. The verbatim finding: "TUI lacks strong positioning as the definitive all-inclusive provider versus being one of many operators in the space." TUI holds ATOL and ABTA credentials that would establish regulatory authority in the category. They are not structured as Layer 3 evidence. Peec AI tells TUI how often it appears. It does not surface the definitiveness failure.
Why the category cannot fix this
This paper does not argue that Profound or Peec AI are doing something wrong. The layer mismatch is a structural property of the category produced by three constraints that operate simultaneously on every company in it.
Wikipedia explicitly prohibits paid editing and brand promotion. Wikidata requires verifiable third-party citations. Both platforms have active editorial communities that revert promotional changes with consistency. A SaaS company cannot ship a knowledge graph optimisation feature because the platforms that constitute Layer 3 reject optimisation as a concept.
The GEO category measures citation frequency because citation frequency is measurable, improvable on a short timeline, and reportable in dashboard form. Decision-stage recommendation outcomes require a structured buying sequence probe methodology — a different measurement architecture entirely. The invisible metric is also the unmeasured and unaddressed metric.
Content production is a recurring, scalable, billable activity. Knowledge graph remediation is a one-time or low-cadence intervention. The business model produces a content-first orientation that is not neutral with respect to where the intervention should occur.
The implication
The layer mismatch is not a gap that more GEO content can close. It is a gap that the wrong kind of content has been trying to close — in some cases making it wider.
The brands that understand this distinction before their competitors do will have a structural advantage that no amount of GEO content spend can replicate. AI purchase recommendation performance is not a content problem. It is a Layer 3 evidence architecture problem that requires a different methodology, a different measurement, and a different commercial model.
The window is open now, before Layer 3 remediation becomes as widely understood as Layer 1 content optimisation is today.
WP-2026-08 is open access at Zenodo: DOI: 10.5281/zenodo.19840293
AIVO Meridian: aivomeridian.com