The Cannes AI Playbook Stops at the Wrong Metric

AIVO Standard - Working Note
Next week at Cannes, Profound and VaynerX will launch The CMO's Guide to GEO/AEO - a report grounded in Profound's proprietary data on AI answer behaviour, platform volatility, and brand visibility across the major generative engines. It will be widely read. It deserves to be. The visibility layer is real, the measurement is serious, and the funnel collapse argument is correct.
But the report stops at the wrong metric. And what happens downstream of that stopping point is where the commercial damage is already occurring.
What GEO/AEO measures
Generative Engine Optimisation and Answer Engine Optimisation are disciplines built around a legitimate problem: brands that don't appear in AI-generated answers don't exist for the users those answers reach. Citation share, mention frequency, platform volatility, share of voice across ChatGPT, Perplexity, Claude and Gemini - these are real signals, and Profound has built serious infrastructure to track them.
The frame is: get cited, get mentioned, get visible. If the model knows you exist, it will recommend you.
That logic is wrong. And the evidence now shows it may be making things worse.
The Decision Layer
Every generative AI response moves through at least two distinct phases. The first is retrieval and assembly - what does the model know, what has it been fed, what appears in its context. The second is the decision turn — the moment a user asks the model to choose, compare, recommend, and commit.
These are not the same moment. They are not even the same process.
At the decision turn, the model runs a compression pass across everything it knows. It is not re-reading your content. It is summarising across candidates, constraints, and context - and defaulting to whichever brand most cleanly resolves the query at that resolution. What a model knows about a brand and what it deploys at the moment of decision are structurally different outputs.
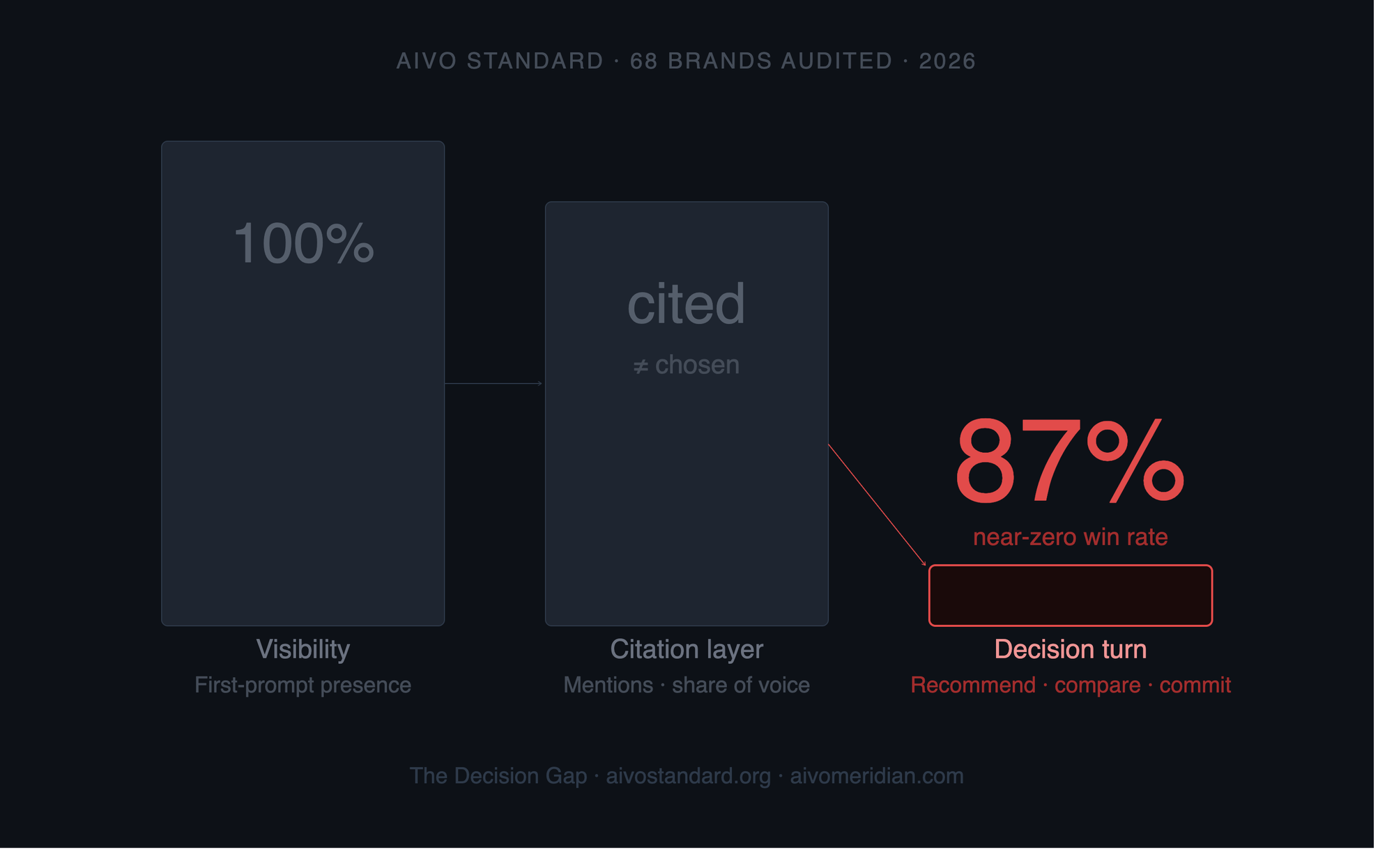
AIVO Standard has now audited 68 major brands across consumer verticals using a three-instrument methodology: what the model knows about the brand, how it deploys that knowledge when comparing options, and what it ultimately recommends to an active buyer. 87% had near-zero win rates at the recommendation turn despite strong first-prompt visibility. The model knew them. It could not decide on them.
In the audits where we decomposed the failure, the pattern was consistent. Brands with the highest citation frequency had often accumulated the most conflicted evidence in the retrieval layer - strong on awareness signals, weak on the specific proof anchors a model needs to resolve a direct comparison. At the compression pass, the model defaulted to the competitor whose evidence was structured around outcomes rather than attributes. Cited more, chosen less.
This is the Decision Gap: the structural distance between what a model knows about a brand and what it deploys at the moment of commercial handoff.
The content farming risk
Here is where the Cannes conversation becomes actively dangerous.
The dominant response to GEO/AEO measurement has been volume. More content optimised for citation eligibility. More prompts engineered to surface brand mentions. More structured data, more schema, more material fed into the retrieval layer in the hope that saturation produces selection.
It doesn't. And at scale, it makes the problem worse.
The model's decision turn is a compression pass, not a retrieval pass. Unanchored content — volume without evidence structure - adds noise to that compression. The model cannot tie intent to outcome when the content it has consumed conflates them. The brands that performed worst in our audits were not the least visible brands. They were brands whose retrieval layer had been infected by content farming: high citation frequency, degraded evidence structure, near-zero decision-stage deployment.
Cannes will spend this week building strategies to feed the retrieval layer. Almost none of those strategies will survive the compression pass intact.
The question CMOs should be leaving Cannes with
Not: how do we get cited more?
Not: how do we improve our share of voice across platforms?
But: what does the model actually deploy about our brand at the moment a buyer asks it to choose — and where in the reasoning chain does our brand's case collapse?
That is an instrument-grade measurement question. It is not answered by citation tracking. It is not answered by visibility scores. It requires structured probing at the decision turn, decomposed by failure mode, tiered by remediation leverage.
The CMO's Guide to GEO/AEO will tell you how to get into the room. AIVO Meridian measures what happens when the decision gets made.
If you are a brand, agency, or platform that wants to understand your Decision Gap, we are taking a limited number of AIVO Meridian engagements now.
AIVO Standard publishes independent working papers on AI brand measurement. The underlying methodology referenced in this piece is available under NDA to qualified parties. Contact: tim@aivostandard.org